摘 要:本发明涉及转基因技术领域,特别涉及一种DNA分子及其应用和获得高根量苎麻植株的方法。该DNA分子为将苎麻BnWOX8基因5端非翻译区翻译起始位点上游的2000~2500bp序列替换为SEQ ID NO:1的序列。本发明将修饰后的DNA分子转入苎麻植株,获得的苎麻株系表现出较高的根系生产量,且对根系中总黄酮含量没有显著影响。
技术要点
1.一种DNA分子,其特征在于,所述DNA分子的碱基序列如SEQID NO:3所示,其为将苎麻BnWOX8基因5’端非翻译区翻译起始位点上游的2000~2500bp序列替换为SEQ ID NO:1的序列。
2..根据权利要求1所述的DNA分子,其特征在于,所述苎麻BnWOX8基因的编码序列如SEQ ID NO:2所示。
3.权利要求1或2所述DNA分子在制备高根量苎麻植株中的应用。
4.一种重组表达载体,其特征在于,其包含权利要求1或2所述DNA分子。
5.一种重组农杆菌菌株,其特征在于,其包含权利要求4所述重组表达载体。
6.一种获得高根量苎麻植株的方法,其特征在于,包括如下步骤:
将苎麻BnWOX8基因5’端非翻译区翻译起始位点上游的2000~2500bp序列替换为SEQ ID NO:1的序列,得到经过修饰的DNA分子;
将经过修饰的DNA分子与表达载体连接,得到重组表达载体;
将重组表达载体转化入农杆菌,得到重组农杆菌菌株;
制备苎麻愈伤组织,将重组农杆菌菌株转化入苎麻愈伤组织,经过分化培养、生根培养,得到高根量苎麻植株。
7.根据权利要求6所述的方法,其特征在于,所述制备苎麻愈伤组织所用愈伤分化培养基为:MS+0.1~1.0mg/L TDZ+0.01~0.1mg/L 2 ,4-D+0.005~0.015mg/L IAA。
8.根据权利要求6所述的方法,其特征在于,所述分化培养所用愈伤分化培养基为:MS+0.1~1.0mg/L TDZ+0.01~0.1mg/L 2 ,4-D+0.005~0 .015mg/L IAA+100~1000mg/L羧苄青霉素+10~100mg/L卡那青霉素。
9.根据权利要求6至8中任一项所述的方法,其特征在于,所述生根培养所用生根培养基为:MS+0.005~0.015mg/L NAA。
10.一种获得高根量苎麻植株的方法,其特征在于,包括如下步骤:
将苎麻BnWOX8基因5’端非翻译区翻译起始位点上游的2000~2500bp序列替换为SEQ ID NO:1的序列,得到经过修饰的DNA分子;
将经过修饰的DNA分子与表达载体连接,得到重组表达载体;
制备苎麻原生质体细胞,利用PEG介导转化法将重组表达载体转入原生质体细胞中,经培养,得到愈伤组织;愈伤组织经过分化培养,筛选得到高根量苎麻植株。
技术领域
本发明涉及转基因技术领域,特别涉及一种DNA分子及其应用和获得高根量苎麻植株的方法。
背景技术
苎麻是我国传统经济作物,长期以来就有用作药材的习惯,尤其在民族医药中占有重要地位。一般用以中药材的苎麻部位是根系。臧巩固等(2002)在《苎麻药用保价价值及其开发前景浅析》中提到,苎麻在内科上主要用于妇科、泌尿科、呼吸系统、消化系统和糖尿病等其他疾病中,其药理在于苎麻根中含有黄酮甙、熊果酸、超氧化物歧化酶(SOD)等物质,其中每100g苎麻根干粉中含有黄酮类物质0.36g、酚类物质0.37g。陈保锋等(2016)在《苎麻药用研究进展》中统计了现已发现苎麻根系中的黄酮种类有11种。张志勇等(2015)在《苎麻根在贵州6个民族中的临床应用研究》中记载,苎麻根在土家、彝、布依、仫佬、傣、侗等民族中有广泛的应用,具有清热解毒、止血、利水、消肿、安胎、接骨等功效。
动物试验证实,黄酮类化合物(维生素P)的抗坏血作用胜过维生素C的10倍。天然黄酮类化合物多以苷类形式存在,并且由于糖的种类、数量、联接位置及联接方式不同可以组成各种各样黄酮苷类。研究表明,黄酮的功效是多方面的,它是一种很强的抗氧剂,可有效清除体内的氧自由基,如花青素可以抑制油脂性过氧化物的全阶段溢出,这种阻止氧化的能力是维生素E的十倍以上,这种抗氧化作用可以阻止细胞的退化、衰老,也可阻止癌症的发生。黄酮可以改善血液循环,可以降低胆固醇,向天果中的黄酮还含有一种PAF抗凝因子,这些作用大大降低了心脑血管疾病的发病率,也可改善心脑血管疾病的症状等。同时,维生素P实际上是一种由黄酮组成的混合物而非单一物质。不同原料中的黄酮类不同进而导致不同原料具有不同的药用效果,例如蜂胶中含有两种独有的成分:5,7-二羟基-3`,4`-二甲基黄酮和5-羟基-4`,7-二甲氧基双氢黄酮,具有抗菌、抗病毒、抗病原虫等功效。银杏叶黄酮则具有抗炎症、抗环腺苷酸乙酯酶活性、抗组胺活性等多种效用。
由此可见,提高苎麻根系中的酚类物质含量对提高苎麻根系的独特药用价值具有重要意义。当前苎麻根系的获取来源于野生苎麻的挖掘和常规苎麻种植两条途径。这两种方式均存在突出的问题,导致难以应集约化加工的需求。一方面是活性成分含量变异大,而且生长缓慢、采集周期过长。野生苎麻生长分散,采集成本非常高。栽培苎麻往往要等10余年的生长后才挖掘根系。另一方面,从土壤中挖掘出来的苎麻根系携带大量泥土,根系也严重木质化,不仅清洗、干燥、粉碎、提取等程序均需要大量人工和物资,而且酚类含量较高的幼嫩根系难以采集到,进一步提高了生产成本。因此,生产中亟需提供一种轻简高效的高黄酮含量苎麻根系的生产方法。
目前已有报道表明淹水处理,能够提高银杏叶片黄酮含量,但干旱也能引起类似的变化,甚至有研究表明土壤水分含量和银杏叶黄酮类物质含量没有显著相关性。水涝胁迫下烟草总黄酮含量无显著变化,但总酚、总生物碱含量上升。水淹处理下豆瓣菜的可溶性蛋白含量较高但干旱处理下的黄酮类物质含量较高。大量研究表明干旱处理可以提高植物地上部黄酮类物质含量。大量研究表明,干湿交替、淹水处理和干旱处理对植物的此生代谢具有显著影响,但不同作物、不同研究、不同区域均有很大差异,研究结论不一致。专利苎麻工厂化育苗方法(CN105052528B)公开了一种苎麻水培育苗的方法,专利一种镉污染水田苎麻修复方法(CN109433819A)公开了一种在水田中收获苎麻根系的方法。在现有技术基础上,还需要开发通过其它途径提高苎麻根系黄酮含量的生产方法。
发明内容
有鉴于此,本发明提供了一种DNA分子及其应用和获得高根量苎麻植株的方法。该方法获得的苎麻株系表现出较高的根系生产量,且对黄酮含量没有显著影响。
为了实现上述发明目的,本发明提供以下技术方案:
本发明提供了一种DNA分子,该DNA分子的碱基序列如SEQ ID NO:3所示,其为将苎麻BnWOX8基因5’端非翻译区翻译起始位点上游的2000~2500bp序列替换为SEQ ID NO:1的序列。
不同种类的植物表现出巨大的再生能力差异。例如,烟草、番茄等植物能表现出非常强大的器官从头再生能力,但是水稻、小麦和玉米等植物的成熟组织则难以进行培养。研究认为WUSCHEL-related homeobox(WOX)转录因子在调控植物根从头再生过程中发挥着重要作用。在模式植物拟南芥中的研究认为,WOX基因及其编码产物对植物激素信号的应答是调控植物根再生的关键。但不同物种或同物种WOX家族不同基因成员对内源生长素的响应能力存在显著差异,而且WOX基因本身存在复杂的调控网络,具有环境特异性。同时,人们已经在植物界中找到了许多WOX基因,仅拟南芥中验证了功能的成员就有10余个。其中拟南芥WOX11~WOX14都与根的发育相关,而这些基因在水稻等作物的同源基因的功能不尽相同。促进苎麻根系生长,首先需要找到能够在其根系中特意表达的WOX基因成员,然后对其进行调控。如何在众多WOX基因家族中找到能够显著调控水培条件下苎麻根系生长的基因,本身具有较大的难度。
启动子(Promoters)是基因的一个组成部分,就像基因的“开关”,决定基因w的活动,控制基因表达(转录)的起始时间和表达的程度。然而启动子本身并不控制基因活动,而是通过与转录因子(transcription factor)结合而控制基因活动的。前期研究发现一个苎麻WOX基因家族成员(命名为BnWOX8)在苎麻根部组织中特异性表达,并且根再生能力存在差异的苎麻种质的启动子区存在序列多态性。因此,本申请通过启动子区的序列编辑,能够调控WOX8基因功能。
进一步,本申请合成了SEQ ID NO.1的序列,并将BnWOX8基因5’端非翻译区,翻译起始位点上游的2000~2500bp序列替换为SEQ ID NO.1的序列。将这个编辑后的BnWOX8基因转入苎麻植株,获得BnWOX8基因超量表达的苎麻突变株系。这个株系表现出较高的根系生产量,且对黄酮含量没有显著影响。
在本发明中,苎麻BnWOX8基因的编码序列如SEQID NO:2所示。本发明还提供了该DNA分子在制备高根量苎麻植株中的应用。本发明还提供了一种重组表达载体,其包含上述DNA分子。本发明还提供了一种重组农杆菌菌株,其包含上述重组表达载体。本发明还提供了一种获得高根量苎麻植株的方法包括如下步骤:
将苎麻BnWOX8基因5端非翻译区翻译起始位点上游的2000~2500bp序列替换为SEQ ID NO:1的序列,得到经过修饰的DNA分子;
将经过修饰的DNA分子与表达载体连接,得到重组表达载体;
将重组表达载体转化入农杆菌,得到重组农杆菌菌株;
制备苎麻愈伤组织,将重组农杆菌菌株转化入苎麻愈伤组织,经过分化培养、生根培养,得到高根量苎麻植株。
作为优选,制备苎麻愈伤组织所用愈伤分化培养基为:MS+0.1~1.0mg/L TDZ+ 0 .01~0.1mg/L 2 ,4-D+0.005~0.015mg/L IAA。
作为优选,分化培养所用愈伤分化培养基为:MS+0.1~1.0mg/L TDZ+0.01~0.1mg/L 2,4-D+0.005~0.015mg/L IAA+100~1000mg/L羧苄青霉素+10~100mg/L卡那青霉素。
作为优选,生根培养所用生根培养基为:MS+0.005~0.015mg/L NAA。
本发明还提供了一种获得高根量苎麻植株的方法,包括如下步骤:
将苎麻BnWOX8基因5’端非翻译区翻译起始位点上游的2000~2500bp序列替换为SEQ ID NO:1的序列,得到经过修饰的DNA分子;
将经过修饰的DNA分子与表达载体连接,得到重组表达载体;
制备苎麻原生质体细胞,利用PEG介导转化法将重组表达载体转入原生质体细胞中,经培养,得到愈伤组织;
愈伤组织经过分化培养,筛选得到高根量苎麻植株。
本发明提供了一种DNA分子及其应用和获得高根量苎麻植株的方法。该DNA分子为将苎麻BnWOX8基因5’端非翻译区翻译起始位点上游的2000~2500bp序列替换为SEQ ID NO:1的序列。本发明具有的技术效果为:
在任何苎麻品种的基础上显著提高水培条件下的根系产量而不影响黄酮等物质含量。现有生产中尚未见针对根系生长或黄酮含量提高的转基因苎麻品种,因而在筛选水培条件下适宜苎麻根系生长且黄酮含量较高的品种时需要花费大量时间、人力、物力成本,且缺乏进一步提高根系产量的方法。例如要找到一个总酚或总黄酮物质组分对消炎具有显著作用的品种,需要先要对大量品种进行含量的筛选,在进行水培适应性的筛选,如果含量和水培适应性不相匹配,则导致筛选失败,扩大筛选范围则成本提高。因此,如果对高黄铜含量的品种进行水培适应性的改造,或者水培适应性和黄酮含量相匹配的品种进行生产力上的优化,能起到显著的节本增效的作用。本发明在研究BnWOX8基因的功能的基础上,获取BnWOX8基因超量表达苎麻植株,该苎麻突变株适宜于水培培养、根系生长发育快,能迅速形成发达的毯状根层,能够使苎麻更有效的适应水培环境,提高根系产量,并对黄酮等目标物的含量没有显著影响。
附图说明
|
|
图1示苎麻水培培养; |
|
|
图2示水培苎麻毯状根系; |
|
|
图3示BnWOX8基因超量表达苎麻株系PCR及GUS染色鉴定; |
|
|
图4示BnWOX8基因超量表达苎麻株系荧光PCR验证。 |
具体实施方式
本发明公开了一种DNA分子及其应用和获得高根量苎麻植株的方法,本领域技术人员可以借鉴本文内容,适当改进工艺参数实现。特别需要指出的是,所有类似的替换和改动对本领域技术人员来说是显而易见的,它们都被视为包括在本发明。本发明的方法及应用已经通过较佳实施例进行了描述,相关人员明显能在不脱离本发明内容、精神和范围内对本文所述的方法和应用进行改动或适当变更与组合,来实现和应用本发明技术。
本发明提供的获得高根量苎麻植株的方法中所用试剂或仪器均可由市场购得。所用苎麻为中苎2品种。
下面结合实施例,进一步阐述本发明:
实施例1:
(1)含pBI21-BnWOX8超量表达载体的重组农杆菌菌株的获得
具体步骤如下:
1).SEQ ID NO .1序列的合成:采用固相亚磷酰胺三酯法合成。SEQ ID NO .1序列如下:
ATTTTATGAATGATCTGTTGATATGTTTTAGACATGTTGATAAGTGGTGCGTTTTTTTCGTTCGATGTG
CGTTGTCTTTTTGAGAAACTGCCAAGTTGGGAATTTGATGGCGTAGATATCTGAGACTTTTGTTGCCTGATGTGCTC GTTTCCATGCTTTTGTTGTTTGGGTAATACTTTTGGCATGTTGATATTTGATTGGCTATTGATTTACTAAACAATGT TTTTATTGGGTTTTATTTTGAAAAATTATCCCCAAAGTTTCAAGTTAATGTCAAATGAACATTTTTTATTGACTTTT CTAGACGAGGTGAGGGGTCAGTATAACTTGCGAGTTAGATACAAGATACAAGGGTTTTCTTGATATTGTTTATCCTT TTGGGGCCTAATTTTACGGTTTAGGCCGTATATAATATTTCAAAATTGTCCTTAAAAGCTAAAATAAATTAAATTTT CAATGTTTCTGTGTCTTTATTTTCATTGGTCATTGTTAAGCGAAGATGATTTGGAGATCAGCCGCGAACGTATCGTA TCGGTTCGGTTACTAAAAACACCCCTCTTCGTCGGCTTATGGTCTTTGTGTCTCAATTGTCTCTGTCTCAATGTCTC ATGTCTCATGTCTCATGTCTCATGTCTCATGTCTCAGTCACTTGTCTCATGTCTCATATTGTTGTTGATGGGTTAGT TCCTTTAGGTTTTGTTCCATTCTGGGTCTCTGTGTGTCTCAGTGCTTTAACTGCGAGTTCTGCCTCATTATAAGCTG AGGGAATGAGATGAGAGATTGATGTACGGGGGGAGAGGAGAATTTTGTTTCGCTTTTTGGTTTATTAAATGTTGATG CCAAAAATACTTTATTATTTTTTGAATAAAGGTAAATTGTCGATTTAAAAAAAAAGTCGACAAAAGTTGGATATAGG ATATAGGAAGGGGCATTGTTCTATGATATATAATTTCTTATGATTTACCAATAGGAAGTTTTATTACGATTTTTTAG AAACTTAATATGTTTTAAGGGATAATTTTATATAATTTTCTCTTGGGTTATATGTTGGTTCAACAATAGCTGTGATA TGTCATTGCTTGGCTGGGTTATTATGTATTTTGTTGAGTTCTACTTTTATTTCACATGCTGTCTCATTTTAAGTTTC ATTTGATACAGAAGTTCGGCTATGAAATAATTCAATTTAATGTACCATTCTTTTAGTTGGCAAATAATCCGCTCGAA TGTTAAAGCGTATAAATTAATATTATCATTGGTACGGTATACAGTATAATGTCCGTTGAAGTTCGCATGTTATGTAT AAAGGGAACGACATTATGGCTAATTGACTGTCTCATGAATTCCATTTTTCCCTATTGCATTTGCTGGTGGGTTTTGA TCTTATTATAAAGCCCTAGCCTAACTCAATCGATTGCCAATTTGATTAATTAGCAAGACAAGTGCGAAAGGATAACC GAAAGCTGATGTGATTTATTGGAAATAAGGATAAGCATGCTTTTATGTGAATCGAAATCCGAGCTTATAGTAAAATG TACGGACGGTTTTGAAACAATTACATAATTATGGAGGGTTTTGAAAGAGCTTCCACTTATAGTGGTTTTGTCAACTT GTTGCAAAATGATGGGTTGTGTGGGACAGTCTTCTTAATCTAATTATGTTAGGTGGTTAAGCAAATTAGTGAAACTT GCCGTAAGTTGCACTACATGTACAGACAAGTCTGGGTCTTTCAGCCAAAATGTCTCAAAAACTAAAGCTACCCAACC CAACATGCTTTGTGTCCGCCAAAACCAGCAAGAGCCCCTTTATTTTTATGCTTGTTTTACTTTCTAGGCTTTTGTTT TGTTTGTTTTTTTGTTTTAACCTTGTGTAATTTATTATTTGGCGTAAAAACTCGAAAACATGTCACATGAGGATTCTACATTATGTCTCAATTTGAGAGGGAAGAAGGAATTAATACGCGACACCATAGTTTAGCAGTAACGTAGTGAAAGTGG TAATTATTAATAACAATAATAATTAGCTGTAACGTAGTGAAAATGGTAATTTTTTGCGCAATTAGCGACGCTGAATG CTACAACACCGCGCTGACCTTCTGAGCCAGCCTCTATATTTGGAACTCTTATTTTATTTTTGGGTCATAACTTGTTA TTTCCTCAAACCCAAAAAGAAAAAGAAAAATTCATTCGCTCGCTCTCTCACTCCACGCAGGTTGGACCACTAATCTT TTGCTCGAGGAACTCCAGAGTCCACAGTATCTGTGTCAGAGGTATTCGCTTTATTCTATATATATATATATATATAT ATATATATGTTAATGGGTTTGGTCGTTGGTTGACAAAATTCAAGGGTTTTGTTTATGAAATTTGAAGGAAGAGACGA GAGCGTAGAAGAAGAAG
2).BnWOX8基因启动子区修饰:
通过同源重组法,将BnWOX8基因5’端非翻译区,翻译起始位点上游的2000~ 2500bp序列替换为SEQ ID NO.1的序列。
BnWOX8基因编码序列如SEQ ID NO .2所示:
ATGTTGTTGGAAGCGGAAAAAGAGGTAGAGAATTTGAGTCCAAATGCAAATACAAACCAAAAAGAAGAA GAAGGGTTTGGAGGTTTGTTTGTGAAAGTGATGACTGACGAACAATTGGAGCTTCTGAGATATCAGATCTCTGTCTA CGCCACCATCTCTGAGCAACTTGCTGACTTACACAAGTCCTTCACTTCCCAACAACATCTTTCTGGAATGAAGTTGG GGAATCTTAACTATGATCCACTAATGGCATATGGCGGCCACAAGATCACTTCAAGGCAGAGGTGGTCTCCATCGCCT GCGCAGCTTCAAGTGCTTGAGCGAATTTTTGACGAAGGTAATGGGACTCCGAGCAAGCAGAAGATCAAGGAGATAAC CACCGAACTCTCTCAACACGGCCAAATTTCTGAAACCAATGTGTACAACTGGTTCCAGAACAGGAGGGCTCGTTCAA AACGGAAGCAGTCAGTCGCAACACCAAACAATGCGGAACCGGAAGCAGAGTCTGAAACTCATGATTTCCTTAAGGAA AATGCGAAACCAGAAGACGCCGAATTCTATGACAACTCCGCAAAACCAAGCAATGATCATGTGTACTTTCCGAGCCC TGAGGAGTTGATAAGTTGGTCGGAAAATGAAAGCGTGATCGAGCTACAACACGCCTTGCCAGCCTGGACAGGATTTG GCGTTGAAGAGCTGTAG
修饰后的BnWOX8基因及5端非编码区序列如SEQ ID NO.3所示:ATTTTATGAATGAT
CTGTTGATATGTTTTAGACATGTTGATAAGTGGTGCGTTTTTTTCGTTCGATGTGCGTTGTCTTTTTGAGAAACTGC CAAGTTGGGAATTTGATGGCGTAGATATCTGAGACTTTTGTTGCCTGATGTGCTCGTTTCCATGCTTTTGTTGTTTG GGTAATACTTTTGGCATGTTGATATTTGATTGGCTATTGATTTACTAAACAATGTTTTTATTGGGTTTTATTTTGAA AAATTATCCCCAAAGTTTCAAGTTAATGTCAAATGAACATTTTTTATTGACTTTTCTAGACGAGGTGAGGGGTCAGT ATAACTTGCGAGTTAGATACAAGATACAAGGGTTTTCTTGATATTGTTTATCCTTTTGGGGCCTAATTTTACGGTTT AGGCCGTATATAATATTTCAAAATTGTCCTTAAAAGCTAAAATAAATTAAATTTTCAATGTTTCTGTGTCTTTATTT TCATTGGTCATTGTTAAGCGAAGATGATTTGGAGATCAGCCGCGAACGTATCGTATCGGTTCGGTTACTAAAAACAC CCCTCTTCGTCGGCTTATGGTCTTTGTGTCTCAATTGTCTCTGTCTCAATGTCTCATGTCTCATGTCTCATGTCTCA TGTCTCATGTCTCAGTCACTTGTCTCATGTCTCATATTGTTGTTGATGGGTTAGTTCCTTTAGGTTTTGTTCCATTC TGGGTCTCTGTGTGTCTCAGTGCTTTAACTGCGAGTTCTGCCTCATTATAAGCTGAGGGAATGAGATGAGAGATTGA TGTACGGGGGGAGAGGAGAATTTTGTTTCGCTTTTTGGTTTATTAAATGTTGATGCCAAAAATACTTTATTATTTTT TGAATAAAGGTAAATTGTCGATTTAAAAAAAAAGTCGACAAAAGTTGGATATAGGATATAGGAAGGGGCATTGTTCT ATGATATATAATTTCTTATGATTTACCAATAGGAAGTTTTATTACGATTTTTTAGAAACTTAATATGTTTTAAGGGA TAATTTTATATAATTTTCTCTTGGGTTATATGTTGGTTCAACAATAGCTGTGATATGTCATTGCTTGGCTGGGTTAT TATGTATTTTGTTGAGTTCTACTTTTATTTCACATGCTGTCTCATTTTAAGTTTCATTTGATACAGAAGTTCGGCTA TGAAATAATTCAATTTAATGTACCATTCTTTTAGTTGGCAAATAATCCGCTCGAATGTTAAAGCGTATAAATTAATA TTATCATTGGTACGGTATACAGTATAATGTCCGTTGAAGTTCGCATGTTATGTATAAAGGGAACGACATTATGGCTAATTGACTGTCTCATGAATTCCATTTTTCCCTATTGCATTTGCTGGTGGGTTTTGATCTTATTATAAAGCCCTAGCCT AACTCAATCGATTGCCAATTTGATTAATTAGCAAGACAAGTGCGAAAGGATAACCGAAAGCTGATGTGATTTATTGG AAATAAGGATAAGCATGCTTTTATGTGAATCGAAATCCGAGCTTATAGTAAAATGTACGGACGGTTTTGAAACAATT ACATAATTATGGAGGGTTTTGAAAGAGCTTCCACTTATAGTGGTTTTGTCAACTTGTTGCAAAATGATGGGTTGTGT GGGACAGTCTTCTTAATCTAATTATGTTAGGTGGTTAAGCAAATTAGTGAAACTTGCCGTAAGTTGCACTACATGTA CAGACAAGTCTGGGTCTTTCAGCCAAAATGTCTCAAAAACTAAAGCTACCCAACCCAACATGCTTTGTGTCCGCCAA AACCAGCAAGAGCCCCTTTATTTTTATGCTTGTTTTACTTTCTAGGCTTTTGTTTTGTTTGTTTTTTTGTTTTAACC TTGTGTAATTTATTATTTGGCGTAAAAACTCGAAAACATGTCACATGAGGATTCTACATTATGTCTCAATTTGAGAG GGAAGAAGGAATTAATACGCGACACCATAGTTTAGCAGTAACGTAGTGAAAGTGGTAATTATTAATAACAATAATAA TTAGCTGTAACGTAGTGAAAATGGTAATTTTTTGCGCAATTAGCGACGCTGAATGCTACAACACCGCGCTGACCTTC TGAGCCAGCCTCTATATTTGGAACTCTTATTTTATTTTTGGGTCATAACTTGTTATTTCCTCAAACCCAAAAAGAAA AAGAAAAATTCATTCGCTCGCTCTCTCACTCCACGCAGGTTGGACCACTAATCTTTTGCTCGAGGAACTCCAGAGTC CACAGTATCTGTGTCAGAGGTATTCGCTTTATTCTATATATATATATATATATATATATATATGTTAATGGGTTTGG TCGTTGGTTGACAAAATTCAAGGGTTTTGTTTATGAAATTTGAAGGAAGAGACGAGAGCGTAGAAGAAGAAGATGTT GTTGGAAGCGGAAAAAGAGGTAGAGAATTTGAGTCCAAATGCAAATACAAACCAAAAAGAAGAAGAAGGGTTTGGAG GTTTGTTTGTGAAAGTGATGACTGACGAACAATTGGAGCTTCTGAGATATCAGATCTCTGTCTACGCCACCATCTCT GAGCAACTTGCTGACTTACACAAGTCCTTCACTTCCCAACAACATCTTTCTGGAATGAAGTTGGGGAATCTTAACTA TGATCCACTAATGGCATATGGCGGCCACAAGATCACTTCAAGGCAGAGGTGGTCTCCATCGCCTGCGCAGCTTCAAG TGCTTGAGCGAATTTTTGACGAAGGTAATGGGACTCCGAGCAAGCAGAAGATCAAGGAGATAACCACCGAACTCTCT CAACACGGCCAAATTTCTGAAACCAATGTGTACAACTGGTTCCAGAACAGGAGGGCTCGTTCAAAACGGAAGCAGTC AGTCGCAACACCAAACAATGCGGAACCGGAAGCAGAGTCTGAAACTCATGATTTCCTTAAGGAAAATGCGAAACCAG AAGACGCCGAATTCTATGACAACTCCGCAAAACCAAGCAATGATCATGTGTACTTTCCGAGCCCTGAGGAGTTGATA AGTTGGTCGGAAAATGAAAGCGTGATCGAGCTACAACACGCCTTGCCAGCCTGGACAGGATTTGGCGTTGAAGAGCT GTAG
3).重组农杆菌菌株的获得
将修饰后的BnWOX8基因编码序列(SEQ ID NO.3所示)与超表达载体pBI121分别进行双酶切,双酶切产物经纯化回收后与T4 DNA连接酶进行连接,得到重组载体;重组载体首先转化大肠杆菌感受态细胞(E.coli DH5α)扩增后,再转入农杆菌LBA4404菌株,获得重组农杆菌菌株。
(2)BnWOX8基因超量表达苎麻株系的获取方法:
1)超表达载体介导的BnWOX8基因超量表达:
在无菌条件下,将苎麻无菌苗叶片切成约1-2cm2的小块,置于愈伤分化培养基(MS+0.5mg/L TDZ+0.03mg/L 2 ,4-D+0.01mg/L IAA)中24℃黑暗培养2天;将叶片愈伤组织与OD600值为0.6的农杆菌液(含pBI21-BnWOX8超量表达载体的重组农杆菌菌株)置于恒温震荡器中共同震荡培养8分钟后,取出叶片愈伤组织置于无菌滤纸上滤干后,再将其置于愈伤培养基中黑暗条件下共培养2天;然后,将共培养的愈伤组织进行脱菌处理,并重新置于愈伤分化培养基(MS+0.5mg/L TDZ+0.03mg/L2 ,4-D+0.01mg/L IAA+500mg/L羧苄青霉素+ 50mg/L卡那青霉素)中,25℃光照下培养约7周,待愈伤苗长出后将愈伤苗转接至生根培养基(MS+ 0.01mg / LNAA)中,促进幼苗生根 ,生成3叶期再生苗后通过GUS染色、Sourthernblot、荧光定量PCR等鉴定出BnWOX8基因超量表达的苎麻突变株系(图1-3)。
2)生长素响应元件修饰介导的BnWOX8基因超量表达:(CRISPR的技术也可以做修饰,以下方法只提供了同源重组法)
制备苎麻原生质体细胞并稀释至1.0×105cells/mL,在2mL离心管中加入100μL原生质体悬浮液和20μL (1μg /μL) 质粒DNA ,混匀;加入等体积40%的PEG 4000溶液(含200mmol/L的甘露醇和100mmol/L的CaCl2 ,pH8.0) ,混匀,于25℃下遮光放置20min;再加入440μL W5溶液,转化终止,于4℃、700r/min离心5min;弃上清,加入1mL W5溶液悬浮沉淀,于25℃下暗培养16h;同样条件下再次离心5min,去掉大部分上清液,用剩余的上清液重悬浮沉淀;转化后的原生质体调至5×105个/mL,分别接种到WPM培养基进行液体浅层法培养(培养液中以甘露醇为渗透压调节剂,甘露醇初始浓度为0.6mol/L,pH 5.8)。在直径为6cm的的培养皿中加入2mL原生质体悬浮液,用Parafilm封住培养皿的口,置于转速为100r/min摇床中25℃暗培养。每周添加1次新鲜培养基,甘露醇浓度从0.6mol/L降至0.4mol/L ,再降至0.2mol/L,再形成2mm左右的愈伤组织后转至MS+0.1mol/L 2 ,4-D+0.01mg/L NAA。筛选获得 BnWOX8基因超量表达苎麻株系。荧光PCR验证结果见图4。
试验例1:
上述实施例1中采用以愈伤组织为外植体的遗传转化法得到的苎麻植株与修饰前的苎麻品种进行土培育苗,修饰前的苎麻品种为中苎2号。同期选用未经修饰的中苎2号进行土培育苗。培育45天后检测根系生物量。
土培方法具体如下:
将本发明获得的苎麻植株打顶,去除顶端优势,促进侧枝生长。当侧枝达到12cm后统一采集,修整,利用常规嫩梢扦插的方法在土壤中扦插育苗。扦插在长沙市望城区国家种质长沙苎麻圃开展。2019年4月20日进行,土壤温度稳定通过15℃,土壤质地为沙壤土,平整作厢,厢宽1.2-1.4m,长度不限,厢面上横开浅插苗条沟,条沟距15cm左右。扦插前用无污染的清水加少量多菌灵(浓度不超过1000倍)浇湿苗床。将削好的插枝在1000倍多菌灵消毒液中浸2min后扦插。扦入深度为1-3cm。插苗后及时浇上含杀菌剂的清水,湿透苗床为止。在苗床上插上间距为1m左右的竹弓,盖好薄膜,薄膜用泥土压实四周,防止水分散失。覆盖高度以薄膜不接触麻苗为准。
为了避免强光直晒苗床,晴天上午7:30用草帘或遮阴网盖在薄膜上,下午5:30以后去掉遮荫物。阴雨天不要遮荫。薄膜覆盖的苗床内温度应控制在18-34℃的范围内,温度过高可直接在遮荫物上喷水或揭开两端薄膜降温,最适温度为25-30℃。保持苗床湿润,薄膜上有密集水珠,如见苗床开始发白,应立即浇水。至麻苗长出3-5cm的白根后,先揭开两端薄膜炼苗,并逐步减少覆盖物。2-3天后可全部揭去覆盖物,但应保持湿润。继续培养约15d (总共45d)后拔出幼苗。并于同期扦插的中苎2号种苗同时测定根量,进行对比。
结果见表1:
表1 苎麻根系生物量测定(干重)

注:*代表同一培养条件下不同苎麻品种根系干重存在显著差异(a=0 .05)。
结果显示获取的BnWOX8基因超量表达苎麻植株根系生长发育快,能迅速形成发达的毯状根层,提高根系产量,并对黄酮等目标物的含量没有显著影响。
试验例2
实施例2中采用以愈伤组织为外植体的遗传转化法得到的苎麻植株与修饰前的苎麻品种进行水培育苗,修饰前的苎麻品种为中苎2号。同期选用未经修饰的中苎2号进行水培育苗。培育45天后检测根系生物量。
水培方法具体如下:
将本发明获得的苎麻植株和普通中苎2号苎麻植株打顶,去除顶端优势,促进侧枝生长。当侧枝达到12cm后统一采集,修整,利用专利苎麻工厂化育苗方法(CN105052528B)公开的苎麻水培育苗的方法培养。培育45天后检测根系生物量。
表2 苎麻根系生物量测定(干重)

注:*代表同一培养条件下不同苎麻品种根系干重存在显著差异(a=0.05)。
结果显示获取的BnWOX8基因超量表达苎麻植株适宜于水培培养,根系生长发育快,能迅速形成发达的毯状根层,能够使苎麻更有效的适应水培环境,提高根系产量,并对黄酮等目标物的含量没有显著影响。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
序列表
<110> 中国农业科学院麻类研究所
<120> 一种DNA分子及其应用和获得高根量苎麻植株的方法
<130> MP1934389
<160> 3
<170> SIPOSequenceListing 1 .0
<210> 1
<211> 2396
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 1
attttatgaa tgatctgttg atatgtttta gacatgttga taagtggtgc gtttttttcg 60 ttcgatgtgc gttgtctttt tgagaaactg ccaagttggg aatttgatgg cgtagatatc 120 tgagactttt gttgcctgat gtgctcgttt ccatgctttt gttgtttggg taatactttt 180 ggcatgttga tatttgattg gctattgatt tactaaacaa tgtttttatt gggttttatt 240 ttgaaaaatt atccccaaag tttcaagtta atgtcaaatg aacatttttt attgactttt 300 ctagacgagg tgaggggtca gtataacttg cgagttagat acaagataca agggttttct 360 tgatattgtt tatccttttg gggcctaatt ttacggttta ggccgtatat aatatttcaa 420 aattgtcctt aaaagctaaa ataaattaaa ttttcaatgt ttctgtgtct ttattttcat 480 tggtcattgt taagcgaaga tgatttggag atcagccgcg aacgtatcgt atcggttcgg 540 ttactaaaaa cacccctctt cgtcggctta tggtctttgt gtctcaattg tctctgtctc 600 aatgtctcat gtctcatgtc tcatgtctca tgtctcatgt ctcagtcact tgtctcatgt 660 ctcatattgt tgttgatggg ttagttcctt taggttttgt tccattctgg gtctctgtgt 720 gtctcagtgc tttaactgcg agttctgcct cattataagc tgagggaatg agatgagaga 780 ttgatgtacg gggggagagg agaattttgt ttcgcttttt ggtttattaa atgttgatgc 840 caaaaatact ttattatttt ttgaataaag gtaaattgtc gatttaaaaa aaaagtcgac 900 aaaagttgga tataggatat aggaaggggc attgttctat gatatataat ttcttatgat 960 ttaccaatag gaagttttat tacgattttt tagaaactta atatgtttta agggataatt 1020 ttatataatt ttctcttggg ttatatgttg gttcaacaat agctgtgata tgtcattgct 1080 tggctgggtt attatgtatt ttgttgagtt ctacttttat ttcacatgct gtctcatttt 1140 aagtttcatt tgatacagaa gttcggctat gaaataattc aatttaatgt accattcttt 1200 tagttggcaa ataatccgct cgaatgttaa agcgtataaa ttaatattat cattggtacg 1260 gtatacagta taatgtccgt tgaagttcgc atgttatgta taaagggaac gacattatgg 1320 ctaattgact gtctcatgaa ttccattttt ccctattgca tttgctggtg ggttttgatc 1380 ttattataaa gccctagcct aactcaatcg attgccaatt tgattaatta gcaagacaag 1440 tgcgaaagga taaccgaaag ctgatgtgat ttattggaaa taaggataag catgctttta 1500 tgtgaatcga aatccgagct tatagtaaaa tgtacggacg gttttgaaac aattacataa 1560 ttatggaggg ttttgaaaga gcttccactt atagtggttt tgtcaacttg ttgcaaaatg 1620
atgggttgtg tgggacagtc ttcttaatct aattatgtta ggtggttaag caaattagtg 1680 aaacttgccg taagttgcac tacatgtaca gacaagtctg ggtctttcag ccaaaatgtc 1740 tcaaaaacta aagctaccca acccaacatg ctttgtgtcc gccaaaacca gcaagagccc 1800 ctttattttt atgcttgttt tactttctag gcttttgttt tgtttgtttt tttgttttaa 1860 ccttgtgtaa tttattattt ggcgtaaaaa ctcgaaaaca tgtcacatga ggattctaca 1920 ttatgtctca atttgagagg gaagaaggaa ttaatacgcg acaccatagt ttagcagtaa 1980 cgtagtgaaa gtggtaatta ttaataacaa taataattag ctgtaacgta gtgaaaatgg 2040 taattttttg cgcaattagc gacgctgaat gctacaacac cgcgctgacc ttctgagcca 2100 gcctctatat ttggaactct tattttattt ttgggtcata acttgttatt tcctcaaacc 2160 caaaaagaaa aagaaaaatt cattcgctcg ctctctcact ccacgcaggt tggaccacta 2220 atcttttgct cgaggaactc cagagtccac agtatctgtg tcagaggtat tcgctttatt 2280 ctatatatat atatatatat atatatatat gttaatgggt ttggtcgttg gttgacaaaa 2340 ttcaagggtt ttgtttatga aatttgaagg aagagacgag agcgtagaag aagaag 2396
<210> 2
<211> 702
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 2
atgttgttgg aagcggaaaa agaggtagag aatttgagtc caaatgcaaa tacaaaccaa 60 aaagaagaag aagggtttgg aggtttgttt gtgaaagtga tgactgacga acaattggag 120 cttctgagat atcagatctc tgtctacgcc accatctctg agcaacttgc tgacttacac 180 aagtccttca cttcccaaca acatctttct ggaatgaagt tggggaatct taactatgat 240 ccactaatgg catatggcgg ccacaagatc acttcaaggc agaggtggtc tccatcgcct 300 gcgcagcttc aagtgcttga gcgaattttt gacgaaggta atgggactcc gagcaagcag 360 aagatcaagg agataaccac cgaactctct caacacggcc aaatttctga aaccaatgtg 420 tacaactggt tccagaacag gagggctcgt tcaaaacgga agcagtcagt cgcaacacca 480 aacaatgcgg aaccggaagc agagtctgaa actcatgatt tccttaagga aaatgcgaaa 540 ccagaagacg ccgaattcta tgacaactcc gcaaaaccaa gcaatgatca tgtgtacttt 600 ccgagccctg aggagttgat aagttggtcg gaaaatgaaa gcgtgatcga gctacaacac 660 gccttgccag cctggacagg atttggcgtt gaagagctgt ag 702
<210> 3
<211> 3098
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
attttatgaa tgatctgttg atatgtttta gacatgttga taagtggtgc gtttttttcg 60 ttcgatgtgc gttgtctttt tgagaaactg ccaagttggg aatttgatgg cgtagatatc 120 tgagactttt gttgcctgat gtgctcgttt ccatgctttt gttgtttggg taatactttt 180 ggcatgttga tatttgattg gctattgatt tactaaacaa tgtttttatt gggttttatt 240
ttgaaaaatt atccccaaag tttcaagtta atgtcaaatg aacatttttt attgactttt 300 ctagacgagg tgaggggtca gtataacttg cgagttagat acaagataca agggttttct 360 tgatattgtt tatccttttg gggcctaatt ttacggttta ggccgtatat aatatttcaa 420 aattgtcctt aaaagctaaa ataaattaaa ttttcaatgt ttctgtgtct ttattttcat 480 tggtcattgt taagcgaaga tgatttggag atcagccgcg aacgtatcgt atcggttcgg 540 ttactaaaaa cacccctctt cgtcggctta tggtctttgt gtctcaattg tctctgtctc 600 aatgtctcat gtctcatgtc tcatgtctca tgtctcatgt ctcagtcact tgtctcatgt 660 ctcatattgt tgttgatggg ttagttcctt taggttttgt tccattctgg gtctctgtgt 720 gtctcagtgc tttaactgcg agttctgcct cattataagc tgagggaatg agatgagaga 780 ttgatgtacg gggggagagg agaattttgt ttcgcttttt ggtttattaa atgttgatgc 840 caaaaatact ttattatttt ttgaataaag gtaaattgtc gatttaaaaa aaaagtcgac 900 aaaagttgga tataggatat aggaaggggc attgttctat gatatataat ttcttatgat 960 ttaccaatag gaagttttat tacgattttt tagaaactta atatgtttta agggataatt 1020 ttatataatt ttctcttggg ttatatgttg gttcaacaat agctgtgata tgtcattgct 1080 tggctgggtt attatgtatt ttgttgagtt ctacttttat ttcacatgct gtctcatttt 1140 aagtttcatt tgatacagaa gttcggctat gaaataattc aatttaatgt accattcttt 1200 tagttggcaa ataatccgct cgaatgttaa agcgtataaa ttaatattat cattggtacg 1260 gtatacagta taatgtccgt tgaagttcgc atgttatgta taaagggaac gacattatgg 1320 ctaattgact gtctcatgaa ttccattttt ccctattgca tttgctggtg ggttttgatc 1380 ttattataaa gccctagcct aactcaatcg attgccaatt tgattaatta gcaagacaag 1440 tgcgaaagga taaccgaaag ctgatgtgat ttattggaaa taaggataag catgctttta 1500 tgtgaatcga aatccgagct tatagtaaaa tgtacggacg gttttgaaac aattacataa 1560 ttatggaggg ttttgaaaga gcttccactt atagtggttt tgtcaacttg ttgcaaaatg 1620 atgggttgtg tgggacagtc ttcttaatct aattatgtta ggtggttaag caaattagtg 1680 aaacttgccg taagttgcac tacatgtaca gacaagtctg ggtctttcag ccaaaatgtc 1740 tcaaaaacta aagctaccca acccaacatg ctttgtgtcc gccaaaacca gcaagagccc 1800 ctttattttt atgcttgttt tactttctag gcttttgttt tgtttgtttt tttgttttaa 1860 ccttgtgtaa tttattattt ggcgtaaaaa ctcgaaaaca tgtcacatga ggattctaca 1920 ttatgtctca atttgagagg gaagaaggaa ttaatacgcg acaccatagt ttagcagtaa 1980 cgtagtgaaa gtggtaatta ttaataacaa taataattag ctgtaacgta gtgaaaatgg 2040 taattttttg cgcaattagc gacgctgaat gctacaacac cgcgctgacc ttctgagcca 2100 gcctctatat ttggaactct tattttattt ttgggtcata acttgttatt tcctcaaacc 2160 caaaaagaaa aagaaaaatt cattcgctcg ctctctcact ccacgcaggt tggaccacta 2220 atcttttgct cgaggaactc cagagtccac agtatctgtg tcagaggtat tcgctttatt 2280 ctatatatat atatatatat atatatatat gttaatgggt ttggtcgttg gttgacaaaa 2340 ttcaagggtt ttgtttatga aatttgaagg aagagacgag agcgtagaag aagaagatgt 2400 tgttggaagc ggaaaaagag gtagagaatt tgagtccaaa tgcaaataca aaccaaaaag 2460 aagaagaagg gtttggaggt ttgtttgtga aagtgatgac tgacgaacaa ttggagcttc 2520 tgagatatca gatctctgtc tacgccacca tctctgagca acttgctgac ttacacaagt 2580
ccttcacttc ccaacaacat ctttctggaa tgaagttggg gaatcttaac tatgatccac 2640 taatggcata tggcggccac aagatcactt caaggcagag gtggtctcca tcgcctgcgc 2700 agcttcaagt gcttgagcga atttttgacg aaggtaatgg gactccgagc aagcagaaga 2760 tcaaggagat aaccaccgaa ctctctcaac acggccaaat ttctgaaacc aatgtgtaca 2820 actggttcca gaacaggagg gctcgttcaa aacggaagca gtcagtcgca acaccaaaca 2880 atgcggaacc ggaagcagag tctgaaactc atgatttcct taaggaaaat gcgaaaccag 2940 aagacgccga attctatgac aactccgcaa aaccaagcaa tgatcatgtg tactttccga 3000 gccctgagga gttgataagt tggtcggaaa atgaaagcgt gatcgagcta caacacgcct 3060 tgccagcctg gacaggattt ggcgttgaag agctgtag 3098
说明书附图

图1

图2
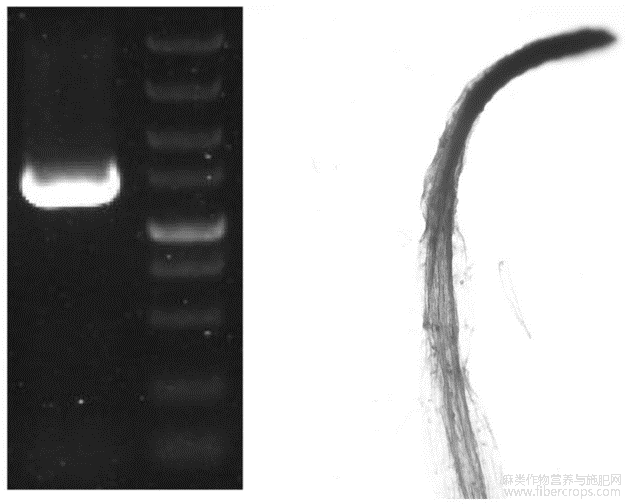
图3

图4
摘自国家发明专利,发明人:高钢,朱爱国,喻春明,陈平,陈坤梅,王晓飞,陈继康,申请号202010552855.0,申请日2020.06.17
