摘 要:本发明公开了一种基于质谱数据的合成大麻素分类和结构解析方法,涉及合成大麻素技术领域,包括以下步骤:S1:称量1.00mg实际缉获样本,用1mL甲醇溶解,超声15mi n后用1mL一次性注射器移取液体并过0.2μmwwPTFE微孔滤膜滤过,用甲醇稀释后供仪器检测;S2:分别使用CID 模式和EAD模式对样品进行全面采集;S3:使用MSConvert开源软件将仪器原始数据文件转换成mzXML的格式,使用MZmi ne开源软件对数据文件进行峰识别、色谱构建、解卷积、同位素过滤和数据导出。本发明质谱智能解析算法包括候选化学结构生成、质谱预测、候选结构评分和碎片离子峰匹配等功能,整个过程无需任何人工干预,实现了新精神活性物质的全面筛查和快速准确检测。
技术要点
1.一种基于质谱数据的合成大麻素分类和结构解析方法,其特征在于:包括以下步骤:
S1:称量1.00mg实际缉获样本,用1mL甲醇溶解,超声15min后用1mL一次性注射器提取液体并过0.2μm wwPTFE微孔滤膜滤过,用甲醇稀释后供仪器检测;
S2:分别使用CID模式和EAD模式对样品进行全面采集;
S3:使用MSConvert开源软件将仪器原始数据文件转换成mzXML的格式,使用MZmine开源软件对数据文件进行峰识别、色谱构建、解卷积、同位素过滤和数据导出,形成csv格式的峰信息文件和mgf格式的MS/MS数据信息文件;
S4:将CID模式下采集的数据经过清洗和标准化后,交由NPS分类模型预测所有峰对应物质的类别,同样将EAD模式下采集的数据经过清洗和标准化后,交由SC亚类分类模型预测 NPS分类模型判定为合成大麻素类物质的亚类类别;
S5:对NPS分类模型判定为合成大麻素类的物质,使用EAD模式下的数据在自建的合成大麻素碎片库中搜索4个部位的结构,生成所有候选化学结构,并根据前体离子的质量进行初步过滤,得到候选结构列表;
S6:根据步骤S4中给出的SC亚类类别,对步骤S5中得到的候选结构列表中的所有结构使用谱图预测算法,生成每个候选结构的预测MS/MS谱图;
S7:使用评分算法根据步骤S6给出的预测MS/MS谱图为每个候选结构进行评分,按照评分从高到低进行排序,排名第一的即为最可能的结构;
S8:在给出最可能的结构之后,软件同样也会给出碎片离子对应的可能碎片结构,完成最终的MS/MS谱图自动解析。
2.根据权利要求1所述的一种基于质谱数据的合成大麻素分类和结构解析方法,其特征在于:所述S2中仪器采集的色谱条件如下:色谱柱:Phenomenex Biphenyl Colum;流动相:A:甲酸水溶液,B:甲酸乙腈溶液;流速、进样量、柱温、样品室温度。
3.根据权利要求1所述的一种基于质谱数据的合成大麻素分类和结构解析方法,其特征在于:所述S3中的MSConvert软件使用Peak Picking功能,算法选择Vendor,MS Level设置为1?2;所述S3中的MZmine软件的详细参数如下:
A1:数据文件导入使用Import MS data,将mzXML文件作为输入;
A2:峰识别使用Mass detection,一级识别参数:保留时间范围1?20min,Polarity为正离子,Mass detector为Centroid,Noise level为1000,二级识别参数:保留时间范围1?20min,Polarity为正离子,Mass detector为Centroid,Noise level为0;
A3:色谱图构建使用ADAP Chromatogram Builder,Minimum consecutive scans为5,Minimumintensity for consecutive scans为2000,Minimum absolute height为5000,CID数据的m/z tolerance为0.002m/z或10ppm,EAD数据的为0.01m/z或50ppm;
A4:解卷积使用Local minimum feature resolver,Chromatographic threshold为85%,Minimum search range RT/Mobility为0.05,Minimum relative height为0%,Minimum absolute height为2000,Min ratio of peak top/edge为2,Peak duration range为0?1,Minimum scans为5;
A5:同位素滤过使用13Cisotope filter,CID数据的m/z tolerance为0.001m/z或 3ppm,EAD数据的为0.01m/z或10ppm,Retention time tolerance为0.02min,Monotonic shape为是,Maximum charge为2,Never remove feature with MS2为是;
A6:数据导出使用Export molecular networking files,导出csv和mgf两个文件。
4.根据权利要求1所述的一种基于质谱数据的合成大麻素分类和结构解析方法,其特征在于:所述S4中的CID数据的清洗和标准化方式如下:使用MATLAB对csv和mgf两个文件进行读取,得到所有峰及其对应的二级质谱数据,所有二级质谱数据按照以下流程进行处理:
B1:将响应归一化至0?100的范围,形成新的二维数组;
B2:分别以0.5%和5%的阈值,删除新的二维数组中响应低于该阈值的数据,形成cut_0.5和cut_5和两个二维数组;
B3:使用cut_5生成假设中性丢失数据,即将cut_5数组任意两个m/z做差,其绝对值作为新的m/z值加入NL数组中,其响应取两个作差值的平均,最后将生成的NL数组增加至cut_0.5数组中;
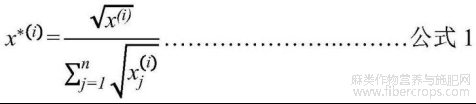
B4:将cut_0.5数组中的响应按照公式1进行标准化,m/z值以四舍五入的方式保留两位小数;
B5:新建一个长度为50000的一维全零数组X[i],值i代表着0.01到500,间隔为0.01的质量数,按照i=m/z*100则X[i]=响应的规则填入cut_0.5数组中的所有数据,最终每个质谱数据均形成一个长度为50000的一维数组,作为分类模型的输入;
所述S4中的EAD数据的清洗和标准化方式如下:使用MATLAB对csv和mgf两个文件进行读取,得到所有峰及其对应的二级质谱数据,EAD质谱数据按照以下流程进行处理:
C1:将响应归一化至0?100的范围,形成新的二维数组;
C2:以0.5和1的阈值,删除新的二维数组中响应低于该阈值的数据,形成cut_0.5和cut_1二维数组;
C3:将cut_0.5数组中的响应按照公式1进行标准化,m/z值以四舍五入的方式保留1位小数;
C4:新建一个长度为5000的一维全零数组X[i],值i代表着0.1到500,间隔为0.1的质量数,按照i=m/z*100则X[i]=响应的规则填入cut_0.5数组中的所有数据,最终每个质谱数据均形成一个长度为5000的一维数组,作为SC亚类分类模型的输入;
C5:cut_1作为合成大麻素碎片库搜索的输入,以生成候选结构列表。
5.根据权利要求1所述的一种基于质谱数据的合成大麻素分类和结构解析方法,其特征在于:所述S5中结构搜索的方式如图3c,得到4个部位的所有可能结构,全排列组合后即可得到若干个可能结构列表,相加4个部位的对应质量与实际MS/MS谱图的前体离子质量进行比较,若质量误差小于0.01Da,则加入候选结构列表,以待进一步的筛选处理。
6.根据权利要求1所述的一种基于质谱数据的合成大麻素分类和结构解析方法,其特征在于:所述S6中的谱图预测算法基于步骤S4给出的SC亚类分类模型给出的类别,按照图4?9的计算方式生成相应结构的预测谱图。
7.根据权利要求1所述的一种基于质谱数据的合成大麻素分类和结构解析方法,其特征在于:所述S7中的评分算法将步骤S6得到的预测MS/MS谱图与实验谱图进行比对,质量容忍误差为0.01Da,一个峰计一分,候选结构以总分进行排序。
8.根据权利要求1所述的一种基于质谱数据的合成大麻素分类和结构解析方法,其特征在于:所述S8中的碎片离子结构预测,即峰匹配,匹配的方式基于所述S7的评分算法,将实验谱图与预测MS/MS谱图成功匹配的峰进行关联,对应结构即为图4?9中的序号对应的结构。
技术领域
本发明涉及合成大麻素技术领域,具体涉及一种基于质谱数据的合成大麻素分类和结构解析方法。
背景技术
新精神活性物质(NPS)是指不受禁毒公约管制但存在滥用并会对公众健康带来威胁的物质,其中,合成大麻素类毒品作为物质种类最多,变异最为迅速的新精神活性物质,目前已达356种,其结构一般由“头部”、“连接(也称颈部)”、“核心(也称躯干)”和“尾部”四个部分组成,给结构修饰提供了多处变异位点,不法分子热衷于对合成大麻素进行结构修饰,不停地“创造”新型结构,以逃避毒品管制目录。针对现有技术存在以下问题:
因为非靶向筛查的过程通常涉及数据采集、可疑峰提取和质谱解析,随着仪器采集技术和数据分析方法的不断进步,越来越多的样本数据需要人工解析,极大地降低了检验鉴定工作的效率的同时也导致了漏检误检等问题,目前,非靶向筛查研究的重点在于提取可疑峰(化合物发现),许多研究人员提出了质谱数据过滤、增强光谱相似性、相似性搜索和片段树等方式,以提高识别可疑峰的准确性,然而,有关自动质谱解析的研究仍然较少,虽然CFM?ID技术可以根据质谱数据预测化学结构,但由于合成大麻素在CID模式下的碎片信息较少,其预测结构的效果有限。
发明内容
本发明提供一种基于质谱数据的合成大麻素分类和结构解析方法,以解决上述背景技术中提出的问题。
为解决上述技术问题,本发明所采用的技术方案是:
一种基于质谱数据的合成大麻素分类和结构解析方法,包括以下步骤:
S1:称量1.00mg实际缉获样本,用1mL甲醇溶解,超声15min后用1mL一次性注射器提取液体并过0.2μm wwPTFE微孔滤膜滤过,用甲醇稀释后供仪器检测;
S2:分别使用CID模式和EAD模式对样品进行全面采集;
S3:使用MSConvert开源软件将仪器原始数据文件转换成mzXML的格式,使用 MZmine开源软件对数据文件进行峰识别、色谱构建、解卷积、同位素过滤和数据导出,形成 csv格式的峰信息文件和mgf格式的MS/MS数据信息文件;
S4:将CID模式下采集的数据经过清洗和标准化后,交由NPS分类模型预测所有峰对应物质的类别,同样将EAD模式下采集的数据经过清洗和标准化后,交由SC亚类分类模型预测NPS分类模型判定为合成大麻素类物质的亚类类别;
S5:对NPS分类模型判定为合成大麻素类的物质,使用EAD模式下的数据在自建的合成大麻素碎片库中搜索4个部位的结构,生成所有候选化学结构,并根据前体离子的质量进行初步过滤,得到候选结构列表;
S6:根据步骤S4中给出的SC亚类类别,对步骤S5中得到的候选结构列表中的所有结构使用谱图预测算法,生成每个候选结构的预测MS/MS谱图;
S7:使用评分算法根据步骤S6给出的预测MS/MS谱图为每个候选结构进行评分,按照评分从高到低进行排序,排名第一的即为最可能的结构;
S8:在给出最可能的结构之后,软件同样也会给出碎片离子对应的可能碎片结构,完成最终的MS/MS谱图自动解析。
本发明技术方案的进一步改进在于:所述S2中仪器采集的色谱条件如下:色谱柱: Phenomenex Biphenyl Colum;流动相:A:甲酸水溶液,B:甲酸乙腈溶液;流速、进样量、柱温、样品室温度。
本发明技术方案的进一步改进在于:所述S3中的MSConvert软件使用Peak Picking功能,算法选择Vendor,MS Level设置为1?2;所述S3中的MZmine软件的详细参数如下:
A1:数据文件导入使用Import MS data,将mzXML文件作为输入;
A2:峰识别使用Mass detection,一级识别参数:保留时间范围1?20min,Polarity 为正离子,Mass detector为Centroid,Noise level为1000,二级识别参数:保留时间范围 1?20min,Polarity为正离子,Mass detector为Centroid,Noise level为0;
A3:色谱图构建使用ADAP Chromatogram Builder,Minimum consecutive scans 为5,Minimumintensity for consecutive scans为2000,Minimum absolute height为 5000,CID数据的m/z tolerance为0.002m/z或10ppm,EAD数据的为0.01m/z或50ppm; [0020] A4:解卷积使用Local minimum feature resolver,Chromatographic threshold 为85%,Minimum search range RT/Mobility为0.05,Minimum relative height为0%, Minimum absolute height为2000,Min ratio of peak top/edge为2,Peak duration range为0?1,Minimum scans为5;
A5:同位素滤过使用13C isotope filter,CID数据的m/z tolerance为0.001m/z 或3ppm,EAD数据的为0.01m/z或10ppm,Retention time tolerance为0.02min,Monotonic shape为是,Maximum charge为2,Never remove feature with MS2为是;
A6:数据导出使用Export molecular networking files,导出csv和mgf两个文件。
本发明技术方案的进一步改进在于:所述S4中的CID数据的清洗和标准化方式如下:使用MATLAB对csv和mgf两个文件进行读取,得到所有峰及其对应的二级质谱数据,所有二级质谱数据按照以下流程进行处理:
B1:将响应归一化至0?100的范围,形成新的二维数组;
B2:分别以0.5%和5%的阈值,删除新的二维数组中响应低于该阈值的数据,形成cut_0.5和cut_5和两个二维数组;
B3:使用cut_5生成假设中性丢失数据,即将cut_5数组任意两个m/z做差,其绝对值作为新的m/z值加入NL数组中,其响应取两个作差值的平均,最后将生成的NL数组增加至cut_0.5数组中;
B4:将cut_0.5数组中的响应按照公式1进行标准化,m/z值以四舍五入的方式保留两位小数;

B5:新建一个长度为50000的一维全零数组X[i],值i代表着0.01到500,间隔为 0.01的质量数,按照i=m/z*100则X[i]=响应的规则填入cut_0.5数组中的所有数据,最终每个质谱数据均形成一个长度为50000的一维数组,作为分类模型的输入;
所述S4中的EAD数据的清洗和标准化方式如下:使用MATLAB对csv和mgf两个文件进行读取,得到所有峰及其对应的二级质谱数据,EAD质谱数据按照以下流程进行处理:
C1:将响应归一化至0?100的范围,形成新的二维数组;
C2:以0.5和1的阈值,删除新的二维数组中响应低于该阈值的数据,形成cut_0.5 和cut_1二维数组;
C3:将cut_0.5数组中的响应按照公式1进行标准化,m/z值以四舍五入的方式保留1位小数;
C4:新建一个长度为5000的一维全零数组X[i],值i代表着0.1到500,间隔为0.1的质量数,按照i=m/z*100则X[i]=响应的规则填入cut_0.5数组中的所有数据,最终每个质谱数据均形成一个长度为5000的一维数组,作为SC亚类分类模型的输入;
C5:cut_1作为合成大麻素碎片库搜索的输入,以生成候选结构列表。
本发明技术方案的进一步改进在于:所述S5中结构搜索的方式如图3c,得到4个部位的所有可能结构,全排列组合后即可得到若干个可能结构列表,相加4个部位的对应质量与实际MS/MS谱图的前体离子质量进行比较,若质量误差小于0.01Da,则加入候选结构列表,以待进一步的筛选处理。
本发明技术方案的进一步改进在于:所述S6中的谱图预测算法基于步骤S4给出的SC亚类分类模型给出的类别,按照图4?9的计算方式生成相应结构的预测谱图。
本发明技术方案的进一步改进在于:所述S7中的评分算法将步骤S6得到的预测 MS/MS谱图与实验谱图进行比对,质量容忍误差为0.01Da,一个峰计一分,候选结构以总分进行排序。
本发明技术方案的进一步改进在于:所述S8中的碎片离子结构预测,即峰匹配,匹配的方式基于所述S7的评分算法,将实验谱图与预测MS/MS谱图成功匹配的峰进行关联,对应结构即为图4?9中的序号对应的结构。
由于采用了上述技术方案,本发明相对现有技术来说,取得的技术进步是:
1、本发明提供一种基于质谱数据的合成大麻素分类和结构解析方法,通过将电子激活解离技术成功应用于合成大麻素类小分子物质,实现了新精神活性物质的非靶向筛查和合成大麻素类物质的自动质谱解析。
2、本发明提供一种基于质谱数据的合成大麻素分类和结构解析方法,质谱智能解析软件集成了NPS分类模型、SC亚类分类模型和质谱智能解析算法,NPS分类模型在505个 NPS的CID数据上进行训练,实现了8类NPS分类预测,最高F1分数达到96%,SC亚类分类模型在181个SC的EAD数据上训练,实现了7类SC母核结构的分类,最高F1分数达到97%。
3、本发明提供一种基于质谱数据的合成大麻素分类和结构解析方法,质谱智能解析算法包括候选化学结构生成、质谱预测、候选结构评分和碎片离子峰匹配等功能,整个过 4/8页程无需任何人工干预,实现了新精神活性物质的全面筛查和快速准确检测。
附图说明
图1为本发明的技术方案流程示意图;
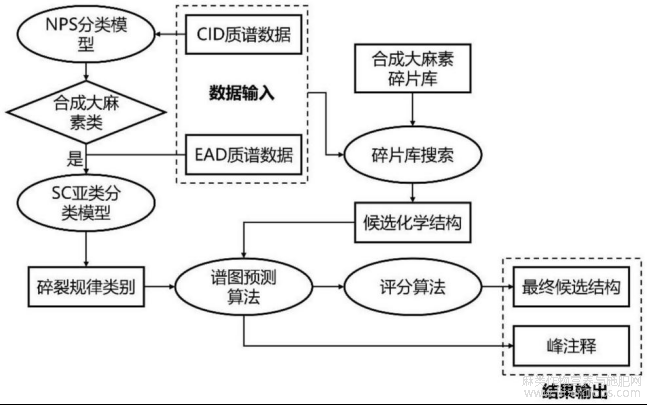
图1
图2为本发明根据EAD碎裂规律总结出的6类合成大麻素母核示意图;
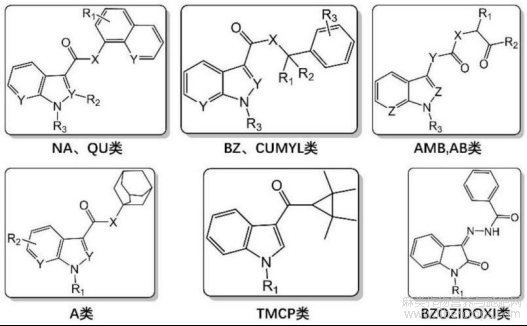
图2
图3中a是JWH?007的MS/MS谱图和碎片结构;b是根据JWH?007的MS/MS图谱总结出的碎片库;c是利用碎片离子质量和假设中性丢失质量在碎片库中进行结构搜索;
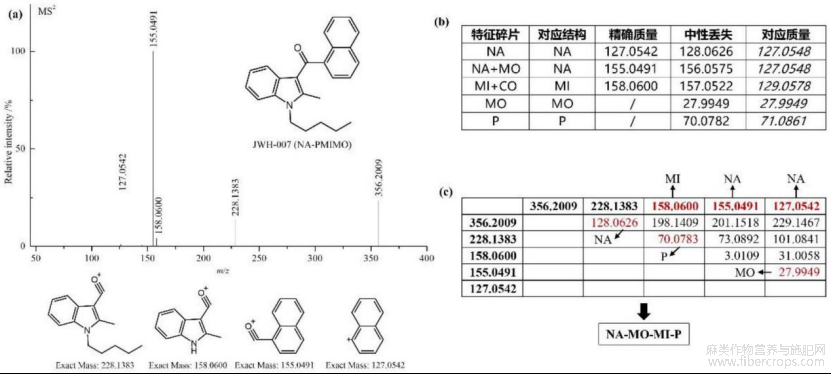
图3
图4为本发明的NA、QU类预测谱图计算方式示意图;
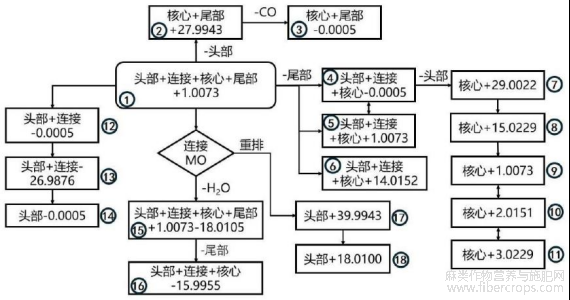
图4
图5为本发明的BZ、CUMYL类预测谱图计算方式示意图;
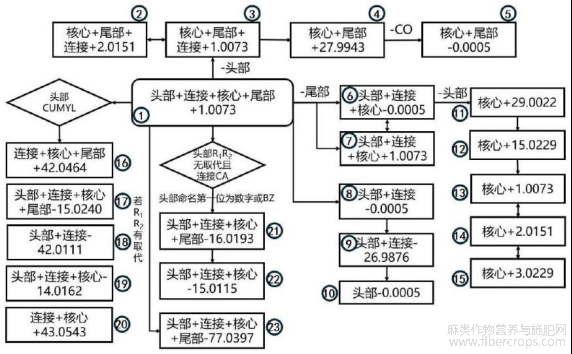
图5
图6为本发明的AB、AMB类预测谱图计算方式示意图;
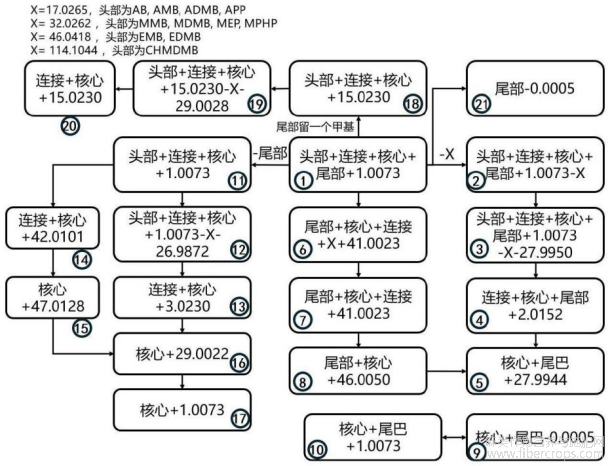
图6
图7为本发明的A类预测谱图计算方式示意图;
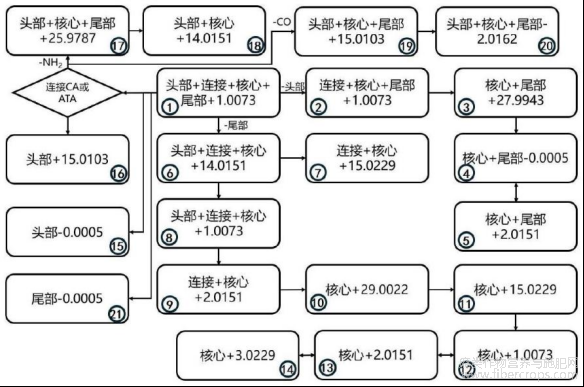
图7
图8为本发明的TMCP类预测谱图计算方式示意图;
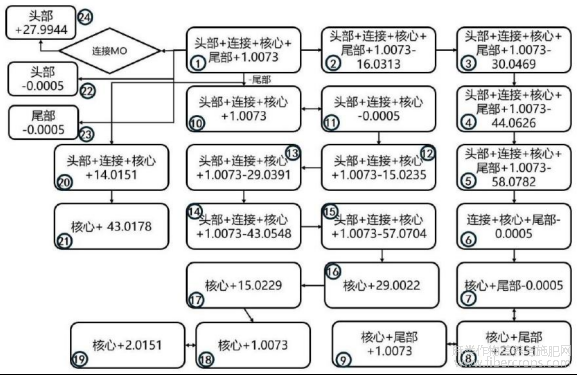
图8
图9为本发明的BZO?ZIDOXI类预测谱图计算方式示意图;
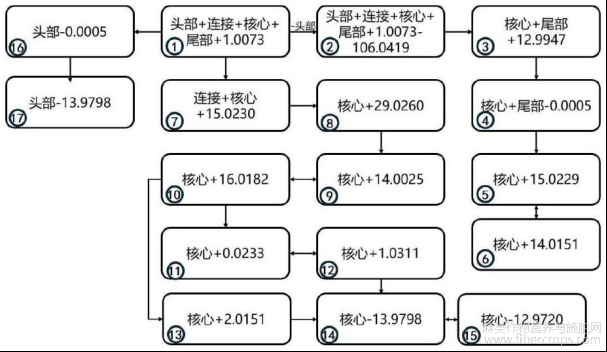
图9
图10为本发明的四种分类模型的混淆矩阵示意图;
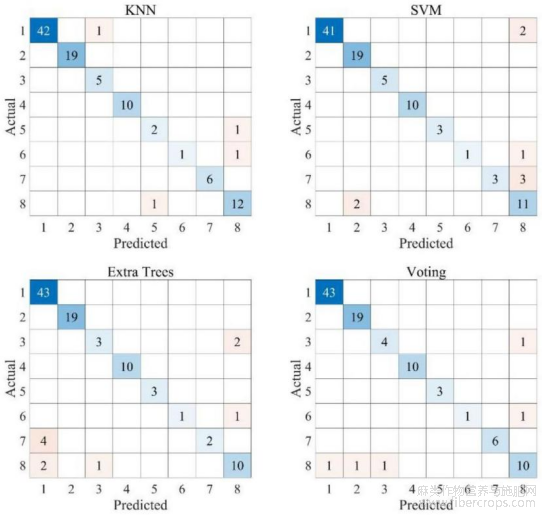
图10
图11为本发明的四个SC亚类分类模型的测试集预测结果的混淆矩阵示意图;
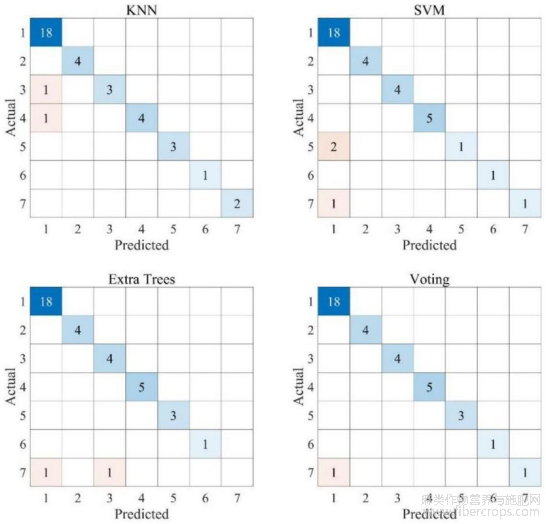
图11
图12为本发明的样本1?1,样本2?5,和样本2?6的化学结构示意图;
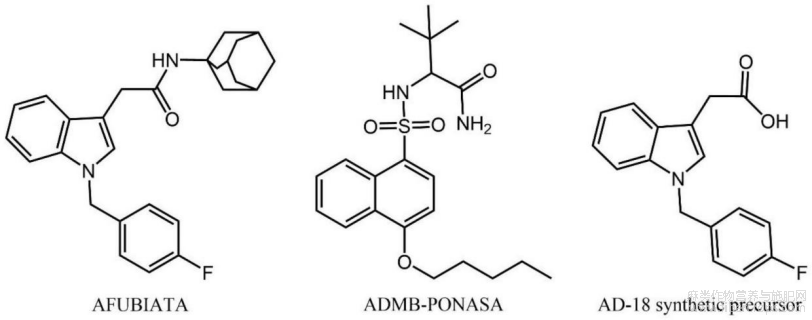
图12
图13为本发明的EAD优化的参数组合示意图;

图13
图14为本发明各个参数组合下的三个评价指标值示意图;
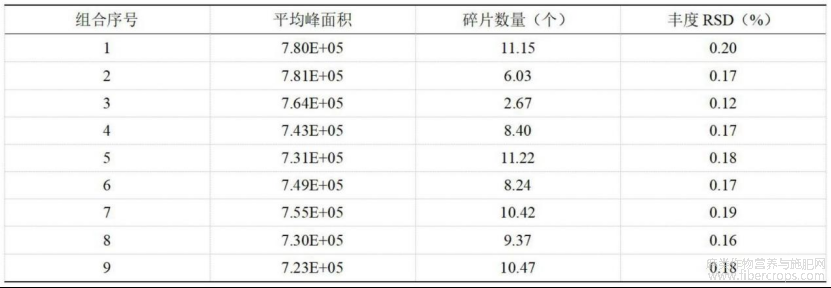
图14
图15为本发明四个NPS分类模型的最优超参数示意图;
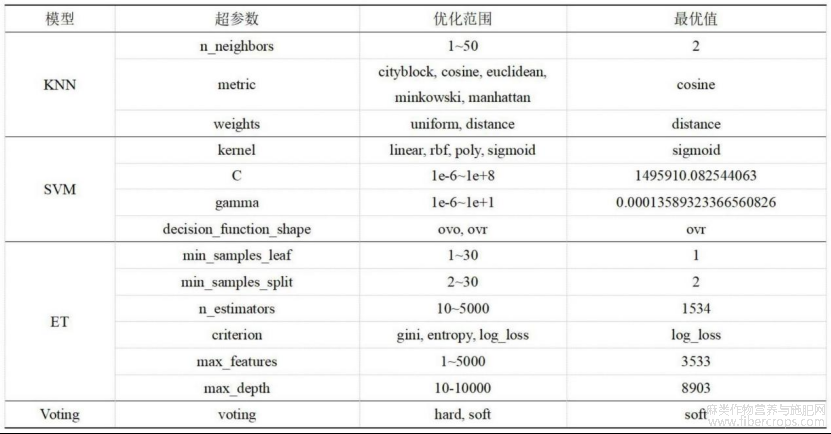
图15
图16为本发明四个SC亚类分类模型最优超参数示意图;
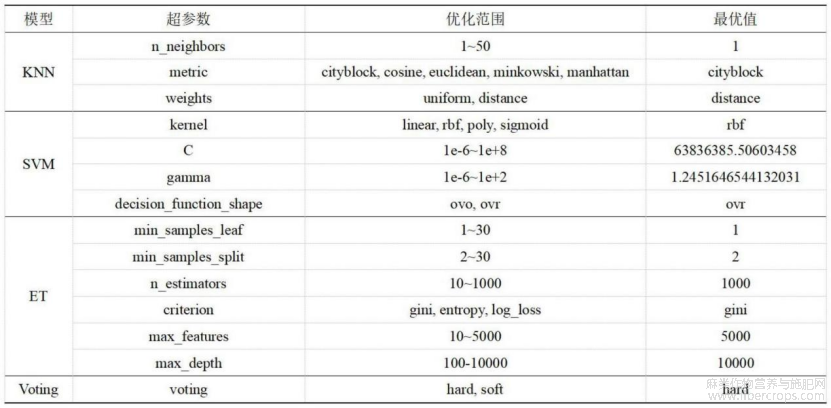
图16
图17为本发明5个实际样品的非靶向筛查结果示意图。
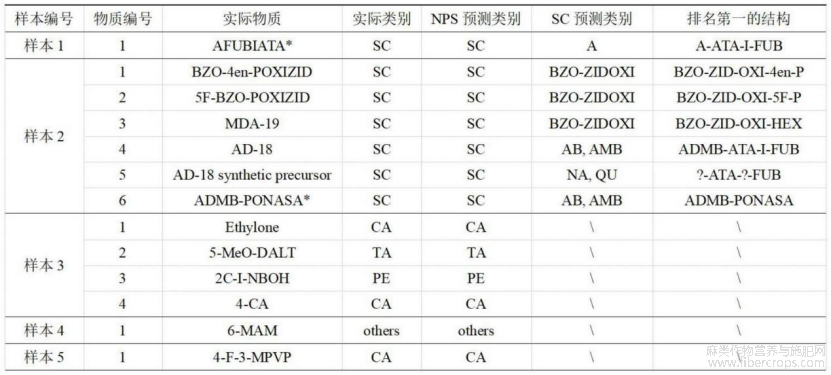
图17
具体实施方式
下面结合实施例对本发明做进一步详细说明:
实施例1
如图1?17所示,本发明提供了一种基于质谱数据的合成大麻素分类和结构解析方法,包括以下步骤:
S1:称量1.00mg实际缉获样本,用1mL甲醇溶解,超声15min后用1mL一次性注射器提取液体并过0.2μm wwPTFE微孔滤膜滤过,用甲醇稀释后供仪器检测;
S2:分别使用CID模式和EAD模式对样品进行全面采集;
S3:使用MSConvert开源软件将仪器原始数据文件转换成mzXML的格式,使用 MZmine开源软件对数据文件进行峰识别、色谱构建、解卷积、同位素过滤和数据导出,形成 csv格式的峰信息文件和mgf格式的MS/MS数据信息文件;
S4:将CID模式下采集的数据经过清洗和标准化后,交由NPS分类模型预测所有峰对应物质的类别,同样将EAD模式下采集的数据经过清洗和标准化后,交由SC亚类分类模型预测NPS分类模型判定为合成大麻素类物质的亚类类别;
S5:对NPS分类模型判定为合成大麻素类的物质,使用EAD模式下的数据在自建的合成大麻素碎片库中搜索4个部位的结构,生成所有候选化学结构,并根据前体离子的质量进行初步过滤,得到候选结构列表;
S6:根据步骤S4中给出的SC亚类类别,对步骤S5中得到的候选结构列表中的所有结构使用谱图预测算法,生成每个候选结构的预测MS/MS谱图;
S7:使用评分算法根据步骤S6给出的预测MS/MS谱图为每个候选结构进行评分,按照评分从高到低进行排序,排名第一的即为最可能的结构;
S8:在给出最可能的结构之后,软件同样也会给出碎片离子对应的可能碎片结构,完成最终的MS/MS谱图自动解析;
所述S2中仪器采集的色谱条件如下:色谱柱:Phenomenex Biphenyl Colum;流动相:A:甲酸水溶液,B:甲酸乙腈溶液;流速、进样量、柱温、样品室温度;所述S3中的MSConvert软件使用Peak Picking功能,算法选择Vendor,MS Level设置为1?2;所述S3中的MZmine软件的详细参数如下:
A1:数据文件导入使用Import MS data,将mzXML文件作为输入;
A2:峰识别使用Mass detection,一级识别参数:保留时间范围1?20min,Polarity 为正离子,Mass detector为Centroid,Noise level为1000,二级识别参数:保留时间范围 1?20min,Polarity为正离子,Mass detector为Centroid,Noise level为0;
A3:色谱图构建使用ADAP Chromatogram Builder,Minimum consecutive scans 为5,Minimumintensity for consecutive scans为2000,Minimum absolute height为 5000,CID数据的m/z tolerance为0.002m/z或10ppm,EAD数据的为0.01m/z或50ppm;
A4:解卷积使用Local minimum feature resolver,Chromatographic threshold 为85%,Minimum search range RT/Mobility为0.05,Minimum relative height为0%, Minimum absolute height为2000,Min ratio of peak top/edge为2,Peak duration range为0?1,Minimum scans为5;
A5:同位素滤过使用13C isotope filter,CID数据的m/z tolerance为0.001m/z 或3ppm,EAD数据的为0.01m/z或10ppm,Retention time tolerance为0.02min,Monotonic shape为是,Maximum charge为2,Never remove feature with MS2为是;
A6:数据导出使用Export molecular networking files,导出csv和mgf两个文件;
所述S4中的CID数据的清洗和标准化方式如下:使用MATLAB对csv和mgf两个文件进行读取,得到所有峰及其对应的二级质谱数据,所有二级质谱数据按照以下流程进行处理:
B1:将响应归一化至0?100的范围,形成新的二维数组;
B2:分别以0.5%和5%的阈值,删除新的二维数组中响应低于该阈值的数据,形成 cut_0.5和cut_5和两个二维数组;
B3:使用cut_5生成假设中性丢失数据,即将cut_5数组任意两个m/z做差,其绝对值作为新的m/z值加入NL数组中,其响应取两个作差值的平均,最后将生成的NL数组增加至 cut_0.5数组中;
B4:将cut_0.5数组中的响应按照公式1进行标准化,m/z值以四舍五入的方式保留两位小数;
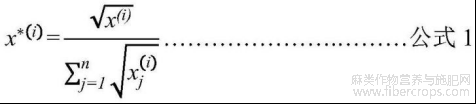
B5:新建一个长度为50000的一维全零数组X[i],值i代表着0.01到500,间隔为 0.01的质量数,按照i=m/z*100则X[i]=响应的规则填入cut_0.5数组中的所有数据,最终每个质谱数据均形成一个长度为50000的一维数组,作为分类模型的输入;
所述S4中的EAD数据的清洗和标准化方式如下:使用MATLAB对csv和mgf两个文件进行读取,得到所有峰及其对应的二级质谱数据,EAD质谱数据按照以下流程进行处理:
C1:将响应归一化至0?100的范围,形成新的二维数组;
C2:以0.5和1的阈值,删除新的二维数组中响应低于该阈值的数据,形成cut_0.5 和cut_1二维数组;
C3:将cut_0.5数组中的响应按照公式1进行标准化,m/z值以四舍五入的方式保留1位小数;
C4:新建一个长度为5000的一维全零数组X[i],值i代表着0.1到500,间隔为0.1的质量数,按照i=m/z*100则X[i]=响应的规则填入cut_0.5数组中的所有数据,最终每个质谱数据均形成一个长度为5000的一维数组,作为SC亚类分类模型的输入;
C5:cut_1作为合成大麻素碎片库搜索的输入,以生成候选结构列表;
所述S5中结构搜索的方式如图3c,得到4个部位的所有可能结构,全排列组合后即可得到若干个可能结构列表,相加4个部位的对应质量与实际MS/MS谱图的前体离子质量进行比较,若质量误差小于0.01Da,则加入候选结构列表,以待进一步的筛选处理;所述S6中的谱图预测算法基于步骤S4给出的SC亚类分类模型给出的类别,按照图4?9的计算方式生成相应结构的预测谱图;所述S7中的评分算法将步骤S6得到的预测MS/MS谱图与实验谱图进行比对,质量容忍误差为0.01Da,一个峰计一分,候选结构以总分进行排序,所述S8中的碎片离子结构预测,即峰匹配,匹配的方式基于所述S7的评分算法,将实验谱图与预测MS/MS谱图成功匹配的峰进行关联,对应结构即为图4?9中的序号对应的结构。
在本实施例中,S2中质谱数据采集自SCIEX ZenoTOFTM 7600超高效液相色谱?质谱联用仪;扫描方式:电喷雾离子源,正离子扫描;检测方式:IDA数据依赖性采集模式;电喷雾电压:5500V;离子源温度:500℃;雾化气压强:50psi;辅助加热气压强:50psi;气帘气压强:35psi;去簇电压:20V,CID模式下的参数如下:碰撞能量:35±15V,EAD模式下的参数如下:电子束能量:15eV;离子传输效率:100%;电子术电流:7500nA;反应时间:50ms;Zeno阱阈值:100000cps;S4中的NPS分类模型和SC亚类分类模型由Python训练得到,均使用Voting 算法,集成了K最近邻、支持向量机和极限森林三种模型,NPS分类模型支持1:合成大麻素类;2:合成卡西酮类;3:苯乙胺类;4:芬太尼类;5:色胺类;6:苯环利定类;7:苯二氮 类;8:其他类共8类NPS的预测分类,SC亚类分类模型支持1:AMB、AB类;2:A类;3:BZ、CUMYL类;4:NA、QU类;5:TMCP类;6:BZO?ZIDOXI类;7:其他类共7类SC母核结构的预测分类,各类母核结构如图2,图2中X=N,O,无;Y=N,C;核心可以进行替换,NA、QU类头部可为其他环。
实施例2
如图1?17所示,在实施例1的基础上,本发明提供一种技术方案:优选的,为了获得更多的碎片信息,本研究针对EAD模式下的质谱参数进行了优化,各个参数选择优化的值分 7/8页别为:电子束能量Electron KE:10eV、15eV、20eV;电子束电流Electron beam current: 6000nA、7500nA、9000nA;离子传输效率ETC:50%、75%、100%;反应时间Reaction time:35ms、50ms、65ms;Zeno阱阈值Zeno threshold:100000cps,具体的优化参数组合见图13,每个参数组合将100ppb的181种合成大麻素重复进样三次,并设定了三个指标用以评价不同 EAD参数组合下谱图质量的优劣:平均峰面积;相对丰度高于1%的碎片数量;三次重复的相同碎片的丰度RSD,采用MATLAB对以上9组参数组合对181种合成大麻素重复采集3次得到的 4887个EAD谱图数据进行处理,受EAD模式下仪器质量精度有所下降的影响,在对同一个合成大麻素的3个EAD谱图进行峰对齐的过程中,设定的误差窗口为0.01Da,计算得到的9组参数的各个指标的值见图14,图14中不同的参数组合的差异主要体现在碎片数量上,平均峰面积和丰度RSD的差异较小,Electron KE值对于谱图质量的影响最大,在KE值由10eV提升至15eV后,碎片离子的数量和丰度都有着显著提升,但是继续提高至20V后,所有的碎片丰度都出现断崖式的下降,实际观察20eV下的EAD谱图发现,大部分合成大麻素的碎片几乎完全消失,只剩下了分子离子峰,这也导致了参数组合3的丰度RSD明显低于其他所有组合,参数Electron beam current和ETC都控制着实际电子的数量,谱图质量和参数取值整体上呈现正相关,因此Electron beam current选择7500nA,ETC选择100%,Electron beam current不选择最高值9000nA的原因是:7500nA提升至9000nA对碎片数量的提升较小;越高的Electron beam current值会导致EAD模式响应衰减得越快,实验发现EAD模式长期处于高电流条件下,会导致质谱EAD和CID模式的整体响应降低,使用负离子质谱方法进行冲洗后,质谱整体响应可以恢复正常,Reaction time的取值对于谱图质量的影响较小,但由于质谱的二级驻留时间需要大于2倍的Reaction time,为了尽量降低方法循环时间,保证方法的稳定性,Reaction time选择为50ms,因此最终选择组合1作为最优参数组合。
实施例3
如图1?17所示,在实施例1的基础上,本发明提供一种技术方案:优选的,选择KNN、SVM、ET、Voting四个分类模型进行优化,模型采用贝叶斯优化算法和5折交叉验证进行训练优化,采用精确度、召回率和f1分数三个指标对模型进行评估,测试集的划分使用python按照0.2的比例随机进行划分,训练集数据404个,测试集数据101个,各个模型的最优超参数组合见图15,各个模型的测试集混淆矩阵如图10,图10中1:合成大麻素类;2:合成卡西酮类;3:苯乙胺类;4:芬太尼类;5:色胺类;6:苯环利定类;7:苯二氮 类;8:其他类,最终选择Voting模型作为最终的NPS分类模型。
实施例4
如图1?17所示,在实施例1的基础上,本发明提供一种技术方案:优选的,选择KNN、SVM、ET和Voting四个分类模型进行优化,模型采用贝叶斯优化算法和5折交叉验证进行优化,采用精确度、召回率和f1分数三个指标对模型进行评估,训练集和测试集的划分采用 Python软件按照0.2的比例随机划分,将181个合成大麻素数据分为144个训练集数据和37 个测试集数据,各个模型的最优超参数组合见图16,各个模型的测试集混淆矩阵如图11,图11中1:AMB、AB类;2:A类;3:BZ、CUMYL类;4:NA、QU类;5:TMCP类;6:BZO?ZIDOXI类;7:其他类,最终选择Voting模型作为最终的SC亚类分类模型,使用上述技术流程对五个实际样品进行了非靶向筛查,结果见图17,五个实际样本中的13种物质全部被NPS分类模型正确分类,使用EAD模式重新采集了样品1和样品2,除样品2?5外,所有物质都被成功解析,正确结构均排在第一位,样品1?1和样品2?6中的两种物质均为新型合成大麻素。
上文一般性地对本发明做了详尽的描述,但在本发明基础上,可以对之做一些修改或改进,这对于技术领域的一般技术人员是显而易见的。因此,在不脱离本发明思想精神的修改或改进,均在本发明的保护范围之内。
文章摘自国家发明专利,一种基于质谱数据的合成大麻素分类和结构,发明人:花镇东,杜宇,贾薇,刘翠梅,黄钰,申请号:202411119803.9,申请日:2024.08.15
