摘 要:本发明提供了一种胡麻籽粒形态识别方法、装置及电子设备。该方法包括:获得待识别胡麻籽粒图像;通过边缘检测算法获得待识别胡麻籽粒图像中各个胡麻籽粒的边缘,获得整体边缘图像;使用目标识别算法获得整体边缘图像中形态完整的胡麻籽粒边缘图像;将形态完整的胡麻籽粒边缘图像从整体边缘图像中进行删除,获得残缺边缘图像;根据残缺边缘图像中各个残缺边缘的曲率对各个残缺边缘进行补齐,获得修正边缘图像;计算形态完整的胡麻籽粒边缘图像和修正边缘图像中各个胡麻籽粒的形态特征值,基于形态特征值输出胡麻籽粒形态识别结果。
权利要求书
1.一种胡麻籽粒形态识别方法,其特征在于,包括:
获得待识别胡麻籽粒图像;
通过边缘检测算法提取待识别胡麻籽粒图像中各个胡麻籽粒的边缘,获得整体边缘图像,包括:
使用直方图均衡化对待识别胡麻籽粒图像进行增强,使用canny边缘检测算法对增强后的待识别胡麻籽粒图像进行边缘检测,获得第一边缘图像;获得待识别胡麻籽粒图像的灰度直方图,从灰度直方图中提取胡麻籽粒边界处的颜色特征值,根据颜色特征值对待识别胡麻籽粒图像进行阈值分割,获得第二边缘图像;将第一边缘图像和第二边缘图像的并集作为整体边缘图像;
使用目标识别算法获得整体边缘图像中形态完整的胡麻籽粒边缘图像,包括:
构建YOLOv5s网络,使用公开数据集对YOLOv5s网络进行训练,获得训练完的YOLOv5s网络;使用少量形态完整的胡麻籽粒边缘图像构建数据集,使用该数据集对训练完的YOLOv5s网络进行微调,获得用于识别形态完整的胡麻籽粒的YOLOv5s网络,使用该YOLOv5s网络对整体边缘图像中形态完整的胡麻籽粒边缘进行识别;
将形态完整的胡麻籽粒边缘图像从整体边缘图像中进行删除,获得残缺边缘图像;根据残缺边缘图像中各个残缺边缘的曲率对各个残缺边缘进行补齐,获得修正边缘图像;
计算形态完整的胡麻籽粒边缘图像和修正边缘图像中各个胡麻籽粒的形态特征值,基于形态特征值输出胡麻籽粒形态识别结果。
2.根据权利要求1所述的胡麻籽粒形态识别方法,其特征在于,所述根据残缺边缘图像中各个残缺边缘的曲率对各个残缺边缘进行补齐,获得修正边缘图像,包括:
使用连通域提取算法获得残缺边缘图像中的各个残缺边缘;根据形态完整的胡麻籽粒边缘构建拟合曲线模型;
计算各个残缺边缘的曲率,将该曲率输入到拟合曲线模型中对残缺边缘进行拟合,通过拟合对残缺边缘的残缺部分进行补齐,获得修正边缘图像。
3.根据权利要求1所述的胡麻籽粒形态识别方法,其特征在于,所述计算形态完整的胡麻籽粒边缘图像和修正边缘图像中各个胡麻籽粒的形态特征值,包括:
使用连通域提取算法获得形态完整的胡麻籽粒边缘图像和修正边缘图像中所有的胡麻籽粒边缘,并获得所有胡麻籽粒边缘的最小外接矩形;
根据胡麻籽粒边缘和最小外接矩形计算各个胡麻籽粒的形态特征值,包括各个胡麻籽粒的周长、面积、长轴长度、短轴长度;
根据各个胡麻籽粒的周长、面积、长轴长度、短轴长度计算整幅待识别胡麻籽粒图像中胡麻籽粒的平均周长、平均面积、平均长轴长度、平均短轴长度及标准差。
4.根据权利要求3所述的胡麻籽粒形态识别方法,其特征在于,所述计算各个胡麻籽粒的形态特征值,包括:
将各个胡麻籽粒边缘的像素个数作为各个胡麻籽粒的周长;
统计各个胡麻籽粒边缘围起来区域的像素个数,将该个数作为对应胡麻籽粒的面积;
将胡麻籽粒边缘最小外接矩形的长作为对应胡麻籽粒的长轴长度;
将胡麻籽粒边缘最小外接矩形的宽作为对应胡麻籽粒的短轴长度。
5.根据权利要求1所述的胡麻籽粒形态识别方法,其特征在于,所述将形态完整的胡麻籽粒边缘图像从整体边缘图像中进行删除,包括:
将整体边缘图像作为二值图像A、形态完整的胡麻籽粒边缘图像作为二值图像B;
将二值图像B中的白色和黑色进行翻转:将白色像素变为黑色,黑色像素变为白色;
对翻转后的二值图像B和二值图像A执行逻辑AND操作:只有在二值图像B和二值图像A对应位置都为白色时,结果图像对应位置是白色。
6.根据权利要求1所述的胡麻籽粒形态识别方法,其特征在于,所述canny边缘检测算法,包括:
使用高斯滤波器平滑图像,去除噪声;
计算平滑后的图像的梯度强度和方向;
通过对某像素点邻域内其它梯度强度值的抑制来实现最大梯度强度值的保留;
选择双阈值检测来确定边缘。
7.一种胡麻籽粒形态识别装置,其特征在于,包括:
图像获取模块,用于获得待识别胡麻籽粒图像;
胡麻籽粒边缘图像获取模块,用于通过边缘检测算法提取待识别胡麻籽粒图像中各个胡麻籽粒的边缘,获得整体边缘图像,包括:
使用直方图均衡化对待识别胡麻籽粒图像进行增强,使用canny边缘检测算法对增强后的待识别胡麻籽粒图像进行边缘检测,获得第一边缘图像;获得待识别胡麻籽粒图像的灰度直方图,从灰度直方图中提取胡麻籽粒边界处的颜色特征值,根据颜色特征值对待识别胡麻籽粒图像进行阈值分割,获得第二边缘图像;将第一边缘图像和第二边缘图像的并集作为整体边缘图像;
用于使用目标识别算法获得整体边缘图像中形态完整的胡麻籽粒边缘图像,包括:构建YOLOv5s网络,使用公开数据集对YOLOv5s网络进行训练,获得训练完的YOLOv5s网络;使用少量形态完整的胡麻籽粒边缘图像构建数据集,使用该数据集对训练完的YOLOv5s网络进行微调,获得用于识别形态完整的胡麻籽粒的YOLOv5s网络,使用该YOLOv5s网络对整体边缘图像中形态完整的胡麻籽粒边缘进行识别;
修正边缘图像获取模块,用于将形态完整的胡麻籽粒边缘图像从整体边缘图像中进行删除,获得残缺边缘图像;根据残缺边缘图像中各个残缺边缘的曲率对各个残缺边缘进行补齐,获得修正边缘图像;
识别模块,用于计算形态完整的胡麻籽粒边缘图像和修正边缘图像中各个胡麻籽粒的形态特征值,基于形态特征值输出胡麻籽粒形态识别结果。
8.一种电子设备,其特征在于,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述权利要求1~6任一所述的方法。
技术领域
本发明涉及图像处理技术领域,特别涉及一种胡麻籽粒形态识别方法、装置及电子设备。
背景技术
胡麻籽粒是一种来源于亚洲胡麻植物(学名:Sesamumindicum)的种子,是一种油料作物。对胡麻籽粒进行形态识别可以帮助鉴别和记录不同胡麻籽粒的形态特征,有助于对不同品种和类型的胡麻进行分类和管理,这对于保护和维护丰富的种质资源起到重要作用,有助于避免基因资源的丧失和品种混淆。
目前,基于机器视觉对胡麻籽粒进行形态识别时,有部分的胡麻籽粒被上层的胡麻籽粒遮盖住,无法获得被遮盖部分的形态,导致仅仅基于上层胡麻籽粒获得的形态特征不具有代表性。为了解决这一问题,CN110363784B公开了一种重叠果实的识别方法,该方法对采集的图像分割获得重叠果实区域,对重叠果实区域进行边缘检测,将边缘检测结果与重叠果实区域进行异或运算,使得重叠果实区域分开,然后使用最小二乘法椭圆检测来对果实的边缘进行拟合,重建被遮挡果实的轮廓。
但是,上述方法边缘检测的准确性可能受到图像质量、光照条件和果实外观等因素的影响,导致边缘检测的结果不准确,从而影响异或运算,导致最终获得的分割结果不够准确或者丢失了一些细节信息。
发明内容
本发明提供一种胡麻籽粒形态识别方法、装置及电子设备,可以解决上述技术问题。
本发明提供一种胡麻籽粒形态识别方法,包括:
获得待识别胡麻籽粒图像;
通过边缘检测算法提取待识别胡麻籽粒图像中各个胡麻籽粒的边缘,获得整体边缘图像,包括:
使用直方图均衡化对待识别胡麻籽粒图像进行增强,使用canny边缘检测算法对增强后的待识别胡麻籽粒图像进行边缘检测,获得第一边缘图像;获得待识别胡麻籽粒图像的灰度直方图,从灰度直方图中提取胡麻籽粒边界处的颜色特征值,根据颜色特征值对待识别胡麻籽粒图像进行阈值分割,获得第二边缘图像;将第一边缘图像和第二边缘图像的并集作为整体边缘图像;
使用目标识别算法获得整体边缘图像中形态完整的胡麻籽粒边缘图像,包括:
构建YOLOv5s网络,使用公开数据集对YOLOv5s网络进行训练,获得训练完的YOLOv5s网络;使用少量形态完整的胡麻籽粒边缘图像构建数据集,使用该数据集对训练完的YOLOv5s网络进行微调,获得用于识别形态完整的胡麻籽粒的YOLOv5s网络,使用该YOLOv5s网络对整体边缘图像中形态完整的胡麻籽粒边缘进行识别;
将形态完整的胡麻籽粒边缘图像从整体边缘图像中进行删除,获得残缺边缘图像;根据残缺边缘图像中各个残缺边缘的曲率对各个残缺边缘进行补齐,获得修正边缘图像;
计算形态完整的胡麻籽粒边缘图像和修正边缘图像中各个胡麻籽粒的形态特征值,基于形态特征值输出胡麻籽粒形态识别结果。
进一步的,所述根据残缺边缘图像中各个残缺边缘的曲率对各个残缺边缘进行补齐,获得修正边缘图像,包括:
使用连通域提取算法获得残缺边缘图像中的各个残缺边缘;
根据形态完整的胡麻籽粒边缘构建拟合曲线模型;
计算各个残缺边缘的曲率,将该曲率输入到拟合曲线模型中对残缺边缘进行拟合,通过拟合对残缺边缘的残缺部分进行补齐,获得修正边缘图像。
进一步的,所述计算形态完整的胡麻籽粒边缘图像和修正边缘图像中各个胡麻籽粒的形态特征值,包括:
使用连通域提取算法获得形态完整的胡麻籽粒边缘图像和修正边缘图像中所有的胡麻籽粒边缘,并获得所有胡麻籽粒边缘的最小外接矩形;
根据胡麻籽粒边缘和最小外接矩形计算各个胡麻籽粒的形态特征值,包括各个胡麻籽粒的周长、面积、长轴长度、短轴长度;
根据各个胡麻籽粒的周长、面积、长轴长度、短轴长度计算整幅待识别胡麻籽粒图像中胡麻籽粒的平均周长、平均面积、平均长轴长度、平均短轴长度及标准差。
进一步的,所述计算各个胡麻籽粒的形态特征值,包括:
将各个胡麻籽粒边缘的像素个数作为各个胡麻籽粒的周长;
统计各个胡麻籽粒边缘围起来区域的像素个数,将该个数作为对应胡麻籽粒的面积;
将胡麻籽粒边缘最小外接矩形的长作为对应胡麻籽粒的长轴长度;
将胡麻籽粒边缘最小外接矩形的宽作为对应胡麻籽粒的短轴长度。
进一步的,所述将形态完整的胡麻籽粒边缘图像从整体边缘图像中进行删除,包括:
将整体边缘图像作为二值图像A、形态完整的胡麻籽粒边缘图像作为二值图像B;
将二值图像B中的白色和黑色进行翻转:将白色像素变为黑色,黑色像素变为白色;
对翻转后的二值图像B和二值图像A执行逻辑AND操作:只有在二值图像B和二值图像A对应位置都为白色时,结果图像对应位置是白色。
进一步的,所述canny边缘检测算法,包括:
使用高斯滤波器平滑图像,去除噪声;
计算平滑后的图像的梯度强度和方向;
通过对某像素点邻域内其它梯度强度值的抑制来实现最大梯度强度值的保留;
选择双阈值检测来确定边缘。
一种胡麻籽粒形态识别装置,包括:
图像获取模块,用于获得待识别胡麻籽粒图像;
胡麻籽粒边缘图像获取模块,用于通过边缘检测算法提取待识别胡麻籽粒图像中各个胡麻籽粒的边缘,获得整体边缘图像,包括:
使用直方图均衡化对待识别胡麻籽粒图像进行增强,使用canny边缘检测算法对增强后的待识别胡麻籽粒图像进行边缘检测,获得第一边缘图像;获得待识别胡麻籽粒图像的灰度直方图,从灰度直方图中提取胡麻籽粒边界处的颜色特征值,根据颜色特征值对待识别胡麻籽粒图像进行阈值分割,获得第二边缘图像;将第一边缘图像和第二边缘图像的并集作为整体边缘图像;
用于使用目标识别算法获得整体边缘图像中形态完整的胡麻籽粒边缘图像,包括:
构建YOLOv5s网络,使用公开数据集对YOLOv5s网络进行训练,获得训练完的YOLOv5s网络;使用少量形态完整的胡麻籽粒边缘图像构建数据集,使用该数据集对训练完的YOLOv5s网络进行微调,获得用于识别形态完整的胡麻籽粒的YOLOv5s网络,使用该YOLOv5s网络对整体边缘图像中形态完整的胡麻籽粒边缘进行识别;
修正边缘图像获取模块,用于将形态完整的胡麻籽粒边缘图像从整体边缘图像中进行删除,获得残缺边缘图像;根据残缺边缘图像中各个残缺边缘的曲率对各个残缺边缘进行补齐,获得修正边缘图像;
识别模块,用于计算形态完整的胡麻籽粒边缘图像和修正边缘图像中各个胡麻籽粒的形态特征值,基于形态特征值输出胡麻籽粒形态识别结果。
一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的胡麻籽粒形态识别方法。
本发明提供一种胡麻籽粒形态识别方法、装置及电子设备,与现有技术相比,其有益效果如下:
本发明通过边缘检测算法和胡麻籽粒边界处的颜色特征值获得了更加清晰完整的整体边缘图像,使用YOLOv5s网络可以从该更加清晰完整的整体边缘图像中精准的获取形态完整的胡麻籽粒边缘图像,基于上述更加清晰完整的整体边缘图像和更加精准的形态完整的胡麻籽粒边缘图像进行异或运算,从而可以获得更加准确的残缺边缘,使得形态识别的结果更加准确。
并且一般使用YOLOv5s获得形态完整的胡麻籽粒边缘图像的步骤是首先使用YOLOv5s获得形态完整的胡麻籽粒,然后对这些胡麻籽进行边缘检测以获得形态完整的胡麻籽粒边缘。但是这样在对YOLOv5s进行训练过程中会引入与边缘的无关因素,导致训练时的计算量较大和识别结果不准确。而本发明首先进行边缘检测然后再识别,不仅可以大幅降低计算量,还可以使得YOLOv5s网络更关注于边缘特征,更加准确的形态完整的胡麻籽粒边缘。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
在附图中:
图1是本说明书提供的流程图;
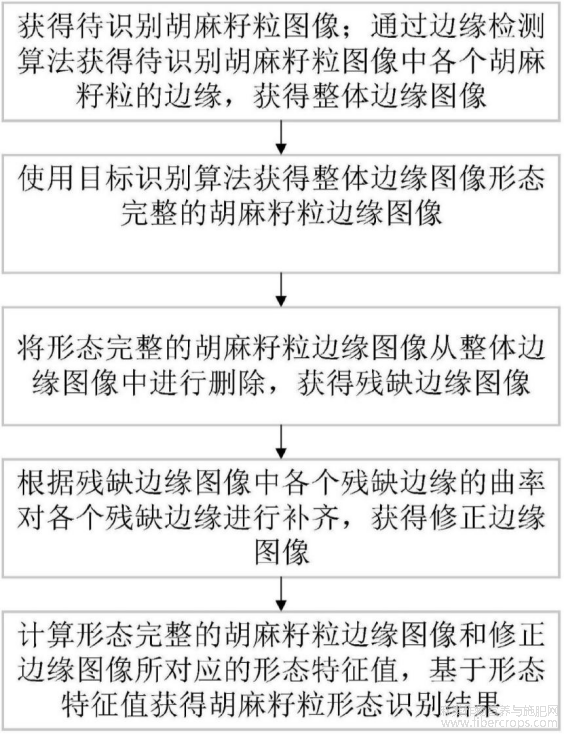
图1
图2是本说明书提供的框架图;
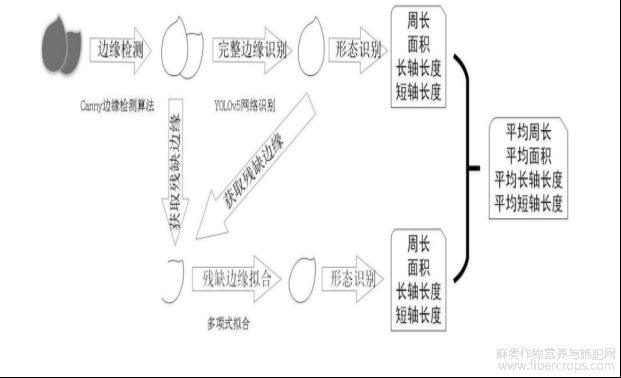
图2
图3图像采集设备示意图;
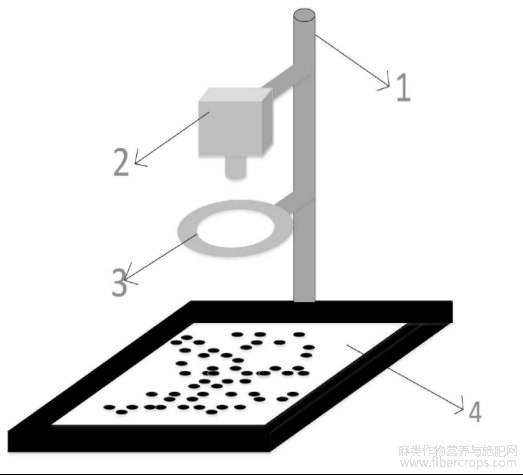
图3
图4是本说明书提供的直方图均衡化原理示意图;

图4
图5是本说明书提供的canny算法的流程图;

图5
图6是本说明书提供的YOLOv5s网络框架图;
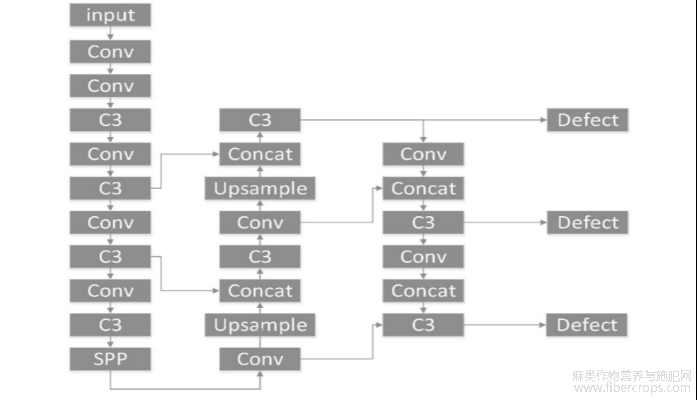
图6
图7是本说明书提供的电子设备示意图。
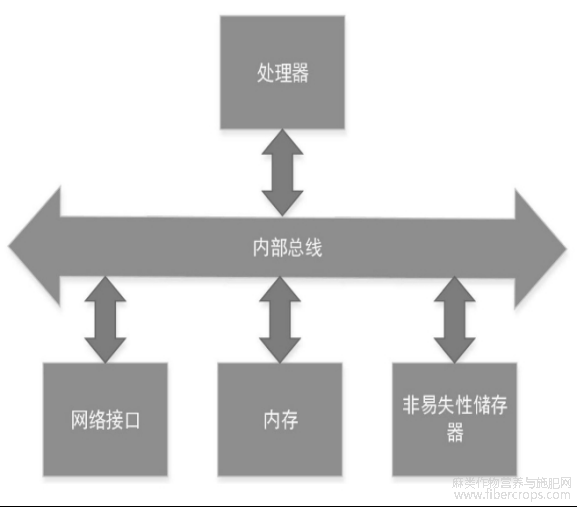
图7
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
实施例
胡麻籽粒是一种来源于亚洲胡麻植物(学名:Sesamumindicum)的种子,是一种油料作物。胡麻是一种古老的农作物,源于近东、地中海沿岸。在中国主要分布在山西、甘肃、宁夏、内蒙古等省、自治区,其种子广泛用于食品加工、药用和油料生产等多个领域。胡麻籽粒的形态通常呈扁平的椭圆形状,大小不一,一般约为2?4毫米长。种子的颜色可以因品种而异,包括白色、黄色、棕色等。胡麻籽粒的表面覆盖有坚硬的种皮,种皮的颜色和纹路因品种而异。对胡麻籽粒进行形态识别具有重要的作用和意义,主要体现在以下几个方面:1.种质资源保护和管理,形态识别可以帮助鉴别和记录不同胡麻籽粒的形态特征,有助于对不同品种和类型的胡麻进行分类和管理,这对于保护和维护丰富的种质资源起到重要作用,有助于避免基因资源的丧失和品种混淆。2.品种鉴别和分类,形态识别是品种鉴别的一种重要手段,通过识别胡麻籽粒的外部形态特征,可以准确确定不同胡麻品种之间的差异,为品种改良和选育提供重要参考信息。3.质量控制和产品认证,胡麻籽粒形态识别可以用于质量控制,确保生产过程中的种子质量。此外,对于一些有特殊用途的胡麻产品,形态识别也可以作为产品认证的依据,保证产品符合特定标准和质量要求。4.病害和虫害防控,形态识别可以帮助检测和鉴别胡麻籽粒上的病害和虫害,通过及时发现并识别这些问题,可以采取有效的防治措施,保障作物的生长和产量。5.市场流通和消费者信任,在胡麻籽粒的市场流通过程中,形态识别可以作为一种验证手段,确保所销售的产品符合标准,并帮助防范假冒伪劣产品。这有助于建立消费者对于产品质量的信任。
近年来,很多学者对胡麻籽粒形态识别方法进行了研究,党照、赵利等人在《利用近红外分析技术测定胡麻种质资源品质》中,利用Perten公司DA7200型近红外透射光谱分析仪,对甘肃胡麻种质资源库的364份胡麻资源的籽粒品质成分进行测定。结果表明,胡麻籽粒4种品质成分在不同材料间存在明显差异,硬脂酸、木酚素、棕榈酸和油酸变异系数较大;碘价、粗脂肪、亚油酸和亚麻酸含量的变异系数较小。资源中粗脂肪平均含量为38.64%,硬脂酸平均含量为4.94%,棕榈酸平均含量为5.58%,油酸、亚油酸、亚麻酸、碘价和木酚素平均含量依次为29.15%、11.4%、51.31%、175.69和9.60mg/g。筛选出了123份优异种质资源供育种利用。并对近红外技术在胡麻品质育种中的利用作了探讨。李建增、杨若菡等人在《外引油用亚麻品种资源鉴定与评价》中,对从荷兰和加拿大引入的油用亚麻品种资源进行综合鉴定、分析与评价。试验材料采用随机区播种,通过多样性、相关性和聚类分析进行研究。主要性状的遗传多样性分析表明,存在较大差异,多样性比较丰富。相关性分析确定了各性状之间的关系。通过系统聚类,把试验材料划分为3大类,为不同育种目标提供依据。赵利、王斌等人在《胡麻种质资源籽粒表型与品质性状评价及其相关性研究》中,测定了238份胡麻资源的8个籽粒表型指标和7个品质性状,探索了它们间的关系,通过对胡麻籽粒形状和种皮颜色的选择实现对胡麻品质性状的间接选择,为胡麻品质育种提供理论依据。随着机器视觉的发展,可以通过采集胡麻籽粒图像对胡麻籽粒进行形态识别。
但是采集的图像中,有部分的胡麻籽粒被上层的胡麻籽粒遮盖住,无法获得被遮盖部分的形态,导致仅仅基于上层胡麻籽粒获得的形态特征不具有代表性。基于此,本申请提出一种胡麻籽粒形态识别方法,首先获得胡麻籽粒的整体边缘图像,该整体边缘图像中既包括形态完整的胡麻籽粒边缘,也包括由于堆叠而导致的残缺边缘图像;接着使用训练好的YOLOv5s神经网路识别形态完整的胡麻籽粒边缘,由于该YOLOv5s神经网路是由形态完整的胡麻籽粒边缘数据集所训练得到的,因此该神经网络可以识别出整体边缘图像中形态完整的胡麻籽粒边缘;通过将整体边缘图像和形态完整的胡麻籽粒边缘图像进行交并集处理后,获得了由于堆叠而导致的残缺边缘,通过对残缺边缘进行多项式拟合,可以获得修正边缘;基于形态完整的胡麻籽粒边缘和修正边缘可以获得整幅图像的形态。该方法将形态完整的胡麻籽粒边缘图像从整体边缘图像中删除,即可获得由于胡麻籽粒堆叠而边缘不完整的胡麻籽粒的边缘,通过对残缺边缘的曲率进行相应的补齐,使得胡麻籽粒的形状更加完整,从而获得了图像中形态完整的胡麻籽粒边缘和修正边缘,即:获得了图像中所有胡麻籽粒的边缘。相对于仅基于最上层胡麻籽粒边缘获得的识别结果,基于图像中所有胡麻籽粒的边缘获得的识别结果包含了被遮挡的胡麻籽粒边缘信息,更具有代表性。
该方法的流程图和框架图分别如图1和图2所示,具体包括以下步骤:
步骤1、采集数据。
确定待识别胡麻籽粒拍摄方案,获取可分辨胡麻籽粒图像。胡麻种子分别为XB1、NM?21?10、ZC?62、ZZ?173、1009?1、08006?375、张亚2号、坝亚21号、同白亚3号等,共计111个品种,由甘肃省农业科学院提供。
图像采集系统由工业相机(维视智造MVHP505GM(500万像素))、环形光源、LED灯板、镜头固定槽、支架、微型计算机(Intel(R)Core(TM)i7?7700HQCPU@2.80GHz、NVIDIAGeForceGTX1060withMax?QDesign、16G内存)等组成,试验采用的系统环境为Windos10、编译环境为Python3.10。该系统可以快速、批量获取胡麻种子图像并进行数据处理分析。图像采集设备示意简图如图3所示,包括支撑杆1,该支撑杆1上设有可旋转、可上下滑动的工业相机2和环形光环3,以及位于底部的LED顶板4。工业相机2位于环形光环3上方,工业相机2透过环形光环3拍摄位于LED板4上的胡麻籽粒。
步骤2、获得整体边缘图像。
本方法观察到各个胡麻籽粒的颜色在边缘、中心和周围区域之间的差异性,因此将胡麻籽自带的边缘颜色特征和边缘梯度特征结合起来,相对于传统的仅基于梯度获得的边缘,该方法可以获得更加准确和清晰的整体边缘图像。首先,可以采用先进的边缘检测算法或锐化算法,例如Canny边缘检测,以确保提取的边缘能够准确地反映胡麻籽粒的形状。进一步利用胡麻籽粒边缘的颜色特征进行阈值分割,通过分析颜色信息并且设定适当的阈值,将图像分割成具有相似颜色特征的区域。这种细致的颜色分割有助于区分胡麻籽粒边缘、中心和周围区域。最后,通过取阈值分割和边缘提取的结果的并集可以得到更完整、更精确的待识别胡麻籽粒图像中所有胡麻籽粒的边缘。这种综合的图像处理方法在实际应用中可以更好地应对不同胡麻籽粒图像的变化和复杂性,提高图像处理的鲁棒性和准确性。考虑到胡麻籽粒之间的黑色区域可以在分割后的图像中进一步处理这些区域,以排除不必要的干扰。例如,可以应用形态学操作,如膨胀和腐蚀,以填充小的空洞或去除细小的颗粒,从而进一步提高图像的清晰度和准确性。具体包括:
步骤2.1、使用直方图均衡化对待识别胡麻籽粒图像进行增强。
直方图均衡化处理的“中心思想”是把原始图像的灰度直方图从比较集中的某个灰度区间变成在全部灰度范围内的均匀分布,即对图像进行非线性拉伸,重新分配图像像素值,使一定灰度范围内的像素数量大致相同,如图4所示。直方图增强可以调整图像的对比度,使得图像中的细微特征更加突出,这样一来,Canny边缘检测算法在增强后的图像上能够更好地捕捉到边缘的细节,从而提高边缘检测的准确性。直方图增强通常可以帮助减少图像中的噪声,并且使得图像更清晰,清晰度的提高有助于Canny算法更好地区分真实的边缘与噪声。直方图增强有助于增强图像中的边缘信息,使得边缘更加连续和清晰,这样一来,Canny算法在增强后的图像上可以产生更加平滑和连续的边缘,避免了边缘中断或断裂的情况。通过直方图增强,图像的特征更加明显,边缘更加清晰,从而使得Canny边缘检测算法在处理图像时更加稳健。这有助于提高边缘检测的鲁棒性,使其对于不同光照条件和噪声的影响更加具有抵抗力。综上所述,对胡麻籽粒图像进行直方图增强后再进行Canny边缘检测可以有效提高边缘检测的准确性、鲁棒性和连续性,从而更好地分析和处理胡麻籽粒图像。图像直方图增强具体包括:
统计待识别胡麻籽粒图像灰度图中每个灰度级别的像素数量,得到图像灰度直方图。在一个灰度级在范围[0,L]的数字图像,其直方图是一个离散函数:

其中,nk是待识别胡麻籽粒图像灰度图中第k个灰度级的像素个数,n是总像素个数,H(k)是第k个灰度级的频率,k=1,2,.,L。
根据H(k)计算累积分布函数,得到H(k)中每个灰度级别的累积分布频率:
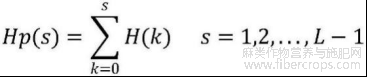
使用累积分布函数的值作为映射函数,将待识别胡麻籽粒图像灰度图中每个像素的灰度级别映射到新的灰度级别:将Hp(s)进行归一化后获得的Hpj(s)乘以L?1再四舍五入,以使得均衡化后图像的灰度级与归一化前的原始图像一致,通过公式new_s=Hpj(s)*(L?1)将原始图像中的像素值s映射为像素值new_s。
步骤2.2、使用canny边缘检测算法对增强后的待识别胡麻籽粒图像进行边缘检测,获得第一边缘图像。
如图5所示,Canny算子在处理图像时主要有以下四个步骤:
使用高斯滤波器平滑图像,去除噪声。所使用的高斯函数为:
|
|
|
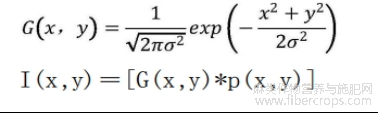
其中,G(x,y)为滤波时所使用的高斯函数,σ为高斯函数的标准差;p(x,y)为输入图像;I(x,y)为经过高斯平滑后的输出图像。
计算平滑后的图像的梯度强度和方向,图像(i,j)处的梯度强度M(i,j)和θ(i,j)方向分别为:
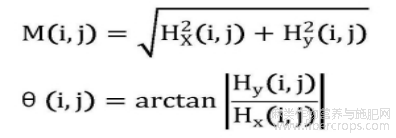
其中,Hx(i,j)表示位于(i,j)的像素在x方向(水平方向)的梯度,Hy(i,j)表示位于(i,j)的像素在y方向(竖直方向)的梯度。
非极大值抑制。非极大值抑制是通过对某像素点邻域内其它梯度强度值的抑制来实现最大梯度强度值的保留。具体操作是:将该像素点的梯度值与邻域内其他点的强度值进行比较,如果当前点的梯度强度值最大,则保留该梯度值,否则令该点的梯度值为0。
选择双阈值检测来确定边缘。根据高低双阈值来检测和连接边缘。人为设定高阈值Tmax和低阈值Tmin,经过非极大值抑制后,如果图像内某像素点的梯度强度值大于Tmax,则该点为强边缘点;若某像素点的梯度强度值小于Tmin,则该像素点为非边缘点;若某像素点的梯度强度值位于Tmin和Tmax之间,则该点为弱边缘点,弱边缘点即可能是边缘点,也可能是由噪声造成的非边缘点,需要结合强边缘点进一步判定。
步骤2.3、获得待识别胡麻籽粒图像的像素直方图,从像素直方图中提取胡麻籽粒边界处的颜色特征值,根据颜色特征值对待识别胡麻籽粒图像进行阈值分割,获得第二边缘图像。
在处理原始待识别的胡麻籽粒图像时,观察到该图像具有明显的颜色差异,这差异在灰度上呈现出明显的峰值。然而直方图增强的操作反而可能导致颜色的动态范围被调整,使得颜色差异减小。考虑到胡麻籽粒的颜色特征对于识别非常关键,因此为了克服直方图增强可能引入的颜色信息损失,选择根据胡麻籽粒边缘的颜色特征对原始待识别胡麻籽粒图像进行阈值分割。这种分割方法允许基于颜色的不同特性将图像中具有相似颜色特征的区域分离开来。通过设定适当的阈值就能够将图像分割成具有明显颜色特征的区域和其他区域。这个阈值分割的结果即为获得的第二边缘图像,这张图像突出了原始图像中的颜色差异,强调了胡麻籽粒边缘的颜色特征。具体包括:
获取像素直方图:对待识别的胡麻籽粒图像进行灰度化,将其转换为灰度图像;计算灰度图像的像素直方图,表示不同灰度级别的像素数量。
提取胡麻籽粒边界处的颜色特征值:从像素直方图中识别具有代表性的灰度峰值,这些峰值对应于胡麻籽粒图像中的颜色特征。可以使用峰值检测算法,如寻找直方图中的局部最大值,以确定颜色特征值。胡麻籽粒边缘处比其它处的颜色浅、灰度值最大,因此将直方图中局部峰值灰度最大及其邻域作为阈值区间。
根据阈值区间进行阈值分割:将待识别的胡麻籽粒图像与阈值区间进行比较,通过简单的二值化,即将灰度值高于阈值区间的像素置为白色,而低于阈值区间的像素置为黑色。
获得第二边缘图像:进行阈值分割后,得到的图像中胡麻籽粒边缘将以明显的形式呈现。这是因为颜色特征值的选择使得胡麻籽粒与其周围环境在图像中有明显的灰度差异。
步骤2.4、将第一边缘图像和第二边缘图像的并集作为整体边缘图像。
由于步骤2.2和步骤2.4获得的第一边缘图像和第二边缘图像均是二值图,因此取这两张二值图的交集作为整体边缘图像,即在两张二值图中均是白色的像素点标记为白色,其余像素点均为黑色。
步骤3、使用目标识别算法(YOLOv5s网络)获得整体边缘图像形态完整的胡麻籽粒边缘图像。
YOLOv5s是一种目标检测算法,它可以准确地定位图像中的目标位置。一般使用YOLOv5s获得形态完整的胡麻籽粒边缘图像的步骤是首先使用YOLOv5s获得形态完整的胡麻籽粒,然后对这些胡麻籽进行边缘检测以获得形态完整的胡麻籽粒边缘。但是这样在对YOLOv5s进行训练过程中会引入与边缘的无关因素,导致训练时的计算量较大和识别结果不准确。本方法首先进行边缘检测然后再识别,不仅可以大幅降低计算量,还可以使得YOLOv5s网络更关注于边缘特征,更加准确的形态完整的胡麻籽粒边缘。通过本发明所设计的流程,可以获得形态学上更完整、更连续的胡麻籽粒边缘,这对于后续形状和大小分析、计数以及其他形态学特征的提取都是有利的。并且结合YOLOv5s的轻量性,能够在相对短的时间内完成目标检测任务,这使得在实时或近实时应用中,可以更迅速地获得胡麻籽粒的边缘信息。更重要的是YOLOv5s提供了便捷的训练脚本和预训练模型,使得用户能够相对容易地针对自己的数据集进行训练,这种简化的训练流程降低了使用门槛,有助于更广泛地应用于不同领域。具体包括:
步骤3.1、构建YOLOv5s网络,使用公开数据集对YOLOv5s网络进行训练,获得训练完的YOLOv5s网络。YOLOv5s网络由图像输入端(Input),主干网络(Backbone),颈部网络(Neck),预测输出层(Head)4个模块组成,如图6所示,各个模块具体包括:
主干网络部分Backbone主要包括Conv结构、C3结构、Focus模块和SPP模块。其中Focus模块在不丢失图片信息的前提下,用切片操作,将图片由三通道转换成12通道,缩小了原图像的尺寸,增大了通道数;类似于邻近下采样生成四张图片,将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。C3模块,是指含有三次卷积操作的CSPBottleneck模块,从模型结构设计的角度解决了推理中计算过多的问题。SPP模块又叫空间金字塔池化(SpatialPyramidPooling),其目的是进行特征融合,采用步长一致但尺寸不同的卷积核实现,是在不影响特征图大小的情况下,对各个尺度的特征图进行最大值池化,得到固定维度的全局特征描述。
颈部网络部分Neck采用特征金字塔网络(FPN,FeaturePyramidNetworks)和路径聚合网络(PAN,PathAggregationNetwork)相结合的结构对不同分辨率的特征图进行多尺度特征融合,并把这些特征传递给预测层。Neck部分模块的目的是为了更好地识别不同尺度的目标。在深度学习领域,不同高度的特征层包含信息的重点不一样,各有优势。高层特征层,语义信息多但是位置信息少,而低层特征层,位置信息多但是语义信息少。在Neck部分利用上采样,下采样操作,将高层和低层特征巧妙地融合起来。不断上采样的操作组合起来叫FPN结构。不断下采样地结构组合起来叫PAN结构。两者的结合,使得整个网络的特征融合能力得到了很大的提升。
预测输出层Head主要负责对Neck网络提取的特征图进行多尺度目标预测,可以预测目标位置、类别、大中小目标的预测和置信度等信息。
构建好后接下来对YOLOv5s网络的预训练,下载YOLOv5s的预训练权重,可以从官方GitHub仓库中获取;利用公开数据集对YOLOv5s进行预训练,以使网络学习一般的目标检测任务。
步骤3.2、使用少量的整体边缘图像构建胡麻籽粒完整边缘数据集,使用该数据集对训练完的YOLOv5s网络进行微调,获得用于识别胡麻籽粒完整边缘的YOLOv5s网络,使用该YOLOv5s网络对整体边缘图像中形态完整的胡麻籽粒边缘进行识别。
使用少量的整体边缘图像构建的数据对训练好的YOLOv5s网络进行微调属于迁移学习。迁移学习允许模型在一个任务上学习到的知识被有效地转移到另一个相关任务上。这样,即使在目标任务的数据量相对较小或有限,模型也能够更快速地学习,并在训练集较小的情况下取得良好的性能。通过使用在大规模数据集上训练过的预训练模型,可以避免从头开始训练模型,从而大大减少训练时间。这对于深度学习等需要大量计算资源的任务尤为重要。并且预训练的模型通常对底层特征和通用模式有很好的学习,这使得模型更具有泛化能力。在新任务中,即使数据分布有所变化,迁移学习的模型也可能更好地适应新的数据分布。在某些情况下,可能存在一个任务的数据量比另一个任务大得多。预训练模型可以从大型任务中学到通用的特征,然后在较小的任务上进行微调,从而缓解数据不平衡的问题。在训练样本较少的情况下,直接在目标任务上训练可能导致过拟合。通过使用预训练模型,可以在更大的数据集上学到通用特征,减轻过拟合的风险。具体包括:
数据准备:获取胡麻籽粒的整体边缘图像数据集,其中包含形态完整的胡麻籽粒边缘信息;将数据集划分为训练集和验证集,确保数据集的多样性和平衡性。
构建胡麻籽粒完整边缘数据集:使用少量整体边缘图像,手动标注形态完整的胡麻籽粒边缘,生成标签文件,通常为YOLO格式的标签文件。
微调YOLOv5s网络:使用预训练的YOLOv5s模型和构建的胡麻籽粒完整边缘数据集对网络进行微调。调整训练参数,如学习率、批次大小等,以适应新的任务。微调的目标是使网络更好地理解和识别胡麻籽粒的形态完整边缘。
模型评估和调优:使用验证集对微调后的模型进行评估,检查其性能。根据评估结果进行调整,可能需要进一步调整模型架构或超参数,以优化模型的准确性。
胡麻籽粒形态完整边缘识别:使用微调完成的YOLOv5s模型对整体边缘图像中的形态完整的胡麻籽粒边缘进行识别。
步骤4、将形态完整的胡麻籽粒边缘图像从整体边缘图像中进行删除,获得残缺边缘图像。
由于形态完整的胡麻籽粒边缘图像和整体边缘图像均是二值图,将整体边缘图像作为二值图像A、形态完整的胡麻籽粒边缘图像作为二值图像B,从二值图像A中删除掉二值图像B的内容通常可以通过图像的逻辑运算来实现。以下是详细的步骤:
获取二值图像A和二值图像B。确保它们具有相同的尺寸和相同的坐标系。
将二值图像B中的白色和黑色进行翻转,即将白色像素变为黑色,黑色像素变为白色。这样做是为了得到B图像的补集,从而能够在A图像中去除B的内容。
对取反后的B图像和A图像执行逻辑AND操作。在这个操作中,只有在两个图像对应位置都为白色时,结果图像对应位置才会是白色。
得到的结果图像即为从A图像中删除了B的内容的图像。在这个结果图像中,B图像中的白色区域被去除,而保留了A图像中的其他内容,即残缺边缘。
对最终得到的残缺边缘图像进行必要的后处理,包括去除噪声、平滑化、增强对比度等步骤,以获得清晰且可用的图像。
步骤5、根据残缺边缘图像中各个残缺边缘的曲率对各个残缺边缘进行补齐,获得修正边缘图像。
使用曲率信息补齐残缺边缘可以增加图像的信息完整性。曲率信息有助于推断边缘的形状和方向,从而更准确地修正边缘的位置。在图像分析和识别任务中,边缘信息通常是关键要素。通过根据曲率信息修正边缘,可以提高边缘的准确性,有助于更准确地进行图像分析和对象识别。当图像中的边缘由于某些原因而缺失或损坏时,通过曲率信息进行补齐可以恢复缺失的边缘,从而实现图像的重建和恢复。具体包括:
步骤5.1、使用连通域提取算法获得残缺边缘图像中的各个残缺边缘,根据各个残缺边缘的像素位置,通过使用数值方法或微分几何方法计算各个残缺边缘的曲率。
步骤5.2、根据胡麻籽粒完整的边缘构建拟合曲线。
对完整的边缘进行曲线拟合,可以采用多项式拟合、样条曲线拟合等方法,以得到完整边缘的数学表示。
步骤5.3、根据各个残缺边缘的曲率,将该曲率输入到拟合曲线中对残缺边缘进行拟合,对残缺边缘的残缺部分进行补齐,获得修正边缘图像。
将计算得到的残缺边缘的曲率和像素位置输入到之前得到的拟合曲线模型中。使用拟合曲线对残缺边缘进行拟合,从而根据输入的曲率和像素位置补齐残缺部分。得到补齐后的完整边缘图像,此时残缺部分已经被拟合曲线修复。
步骤6、计算形态完整的胡麻籽粒边缘图像和修正边缘图像所对应的形态特征值。
步骤6.1、使用连通域提取算法获得形态完整的胡麻籽粒边缘图像和修正边缘图像中的所有单个形态完整的胡麻籽粒边缘和所有单个修正边缘。
由步骤3得到了形态完整的胡麻籽粒边缘图像,即待识别胡麻籽粒图像中最上层的胡麻籽粒边缘图像,由步骤5获得了补齐修正的胡麻籽粒边缘图像,即被遮盖的胡麻籽粒边缘图像。
使用连通域算法获得两张图像中的各个胡麻籽粒的边缘。
步骤6.2、计算所有单个形态完整的胡麻籽粒边缘和所有单个修正边缘的形态特征值,包括:
将各个胡麻籽粒边缘的像素个数作为各个胡麻籽粒的周长。
统计各个胡麻籽粒边缘围起来区域的像素个数,将该个数作为对应胡麻籽粒的面积。
将胡麻籽粒边缘最小外接矩形的长作为对应胡麻籽粒的长轴长度。
将胡麻籽粒边缘最小外接矩形的宽作为对应胡麻籽粒的短轴长度。
步骤6.3、根据各个胡麻籽粒的周长、面积、长轴长度、短轴长度计算整幅待识别胡麻籽粒图像中胡麻籽粒的平均周长、平均面积、平均长轴长度、平均短轴长度及标准差,得到群体平均形态特征值。
本说明书提供的方法具有以下好处:1.提高图像识别准确性:通过使用边缘检测算法和目标识别算法,可以获得胡麻籽粒的整体边缘图像,并筛选出形态完整的边缘图像。这有助于减少噪音和不相关信息,提高了后续形态分析和识别的准确性。2.精细边缘提取:通过删除形态完整的边缘图像,得到残缺边缘图像,使得算法更关注那些可能存在缺陷或特殊形状的部分。这有助于提高识别系统对于不同形态的胡麻籽粒的敏感性。3.自动化缺陷修复:根据残缺边缘图像中的曲率信息对各个残缺边缘进行补齐,有助于自动修复图像中的缺陷,提高图像的完整性和质量。4.形态特征分析:通过计算形态完整的胡麻籽粒边缘图像和修正边缘图像的形态特征值,可以建立一个更全面的特征向量,用于形态学特征分析。这有助于更准确地描述和区分不同形状和结构的胡麻籽粒。5.提高自动化识别效率:整个流程的自动化性质有助于提高胡麻籽粒形态识别的效率,减少了人工操作的需求,适用于大规模图像处理任务。
本说明书提供了一种胡麻籽粒形态识别装置,包括:
图像获取模块,用于获得待识别胡麻籽粒图像;
胡麻籽粒边缘图像获取模块,用于通过边缘检测算法提取待识别胡麻籽粒图像中各个胡麻籽粒的边缘,获得整体边缘图像;使用目标识别算法获得整体边缘图像中形态完整的胡麻籽粒边缘图像;
修正边缘图像获取模块,用于将形态完整的胡麻籽粒边缘图像从整体边缘图像中进行删除,获得残缺边缘图像;根据残缺边缘图像中各个残缺边缘的曲率对各个残缺边缘进行补齐,获得修正边缘图像;
识别模块,用于计算形态完整的胡麻籽粒边缘图像和修正边缘图像中各个胡麻籽粒的形态特征值,基于形态特征值输出胡麻籽粒形态识别结果。
关于胡麻籽粒形态识别装置的具体限定可以参见上文中对于胡麻籽粒形态识别方法的限定,在此不再赘述。上述胡麻籽粒形态识别装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于电子设备中的处理器中,也可以以软件形式存储于电子设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
本说明书还提供了图7所示的电子设备的结构示意图,如图7所示,在硬件层面,该电子设备包括处理器、内部总线、网络接口、内存以及非易失性存储器,当然还可能包括其他业务所需要的硬件。处理器从非易失性存储器中读取对应的计算机程序到内存中然后运行,以实现上述的胡麻籽粒形态识别方法。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。非易失性存储器可包括只读存储器(Read?OnlyMemory,ROM)、磁带、软盘、闪存或光存储器等。易失性存储器可包括随机存取存储器(RandomAccesMemory,RAM)或外部高速缓冲存储器。作为说明而非局限,RAM可以是多种形式,比如静态随机存取存储器(Static RandomAcces Memory,SRAM)或动态随机存取存储器(Dynamic RandomAcces Memory,DRAM)等。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
文章摘自国家发明专利,一种胡麻籽粒形态识别方法、装置及电子设备,发明人:韩俊英,刘成忠,毛永文;申请号,202410409645.4;申请日,2024.04.07
